







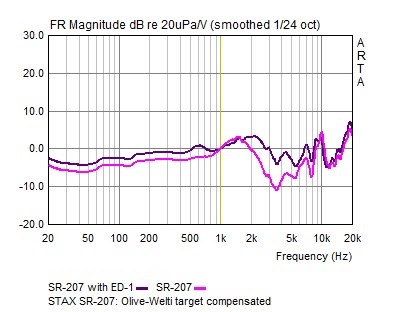




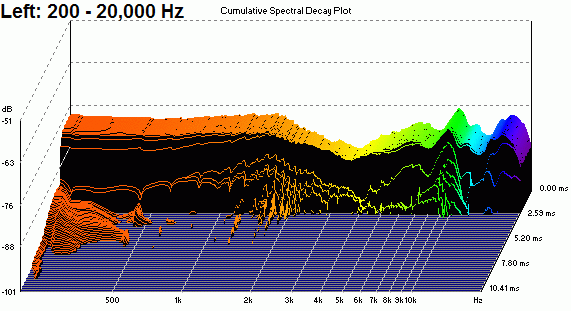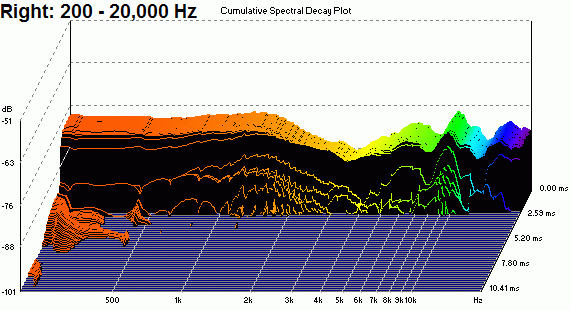

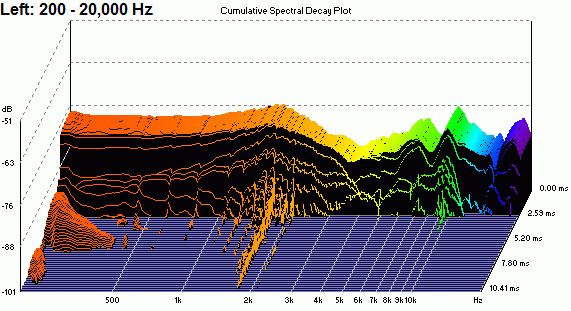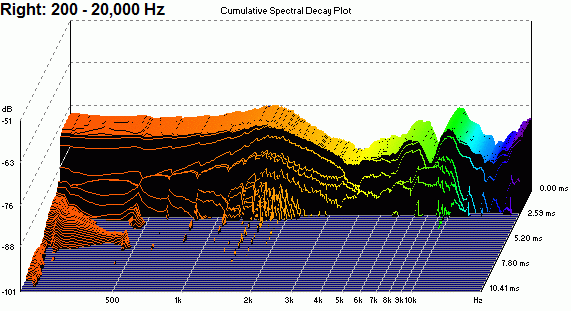

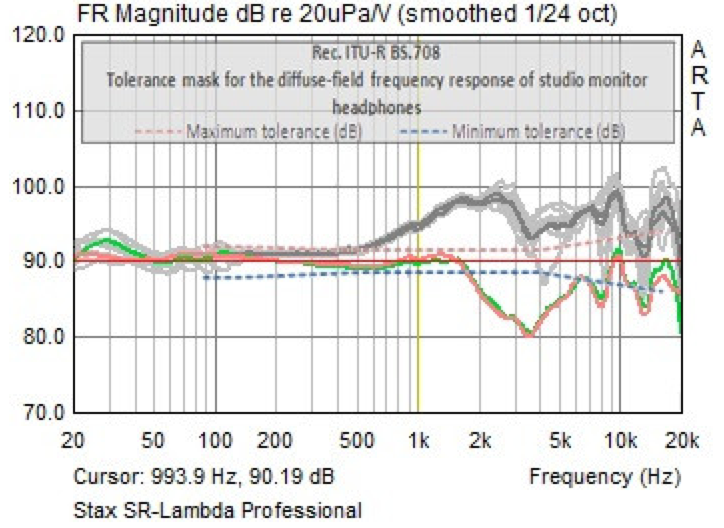

jgazal
500+ Head-Fier
- Joined
- Nov 28, 2006
- Posts
- 730
- Likes
- 136
Forget for a while electronic amplification. Instead, just think sounds we hear in the real world. Once I bought a chorus seat at Sao Paulo Concert Hall, Brazil. It was awful, because all the hall acoustics is planned to direct the sound to the front and I was at the rear very close to the timpani. They sell that seat at very cheap prices. They know that if you stay there you are going to hear everything wrong. Percussion and brass to close. Violins, cellos and winds firing to the front. Everything was deafening.
Go back to electronic reproduction. Imagine that you want to record at Cape Canaveral the space shuttle going to the International Space Station. You want to record those massive solid fuel tanks getting burned to beat the gravitational force. You are going to have a quiet place (okay, imagine that you don't have wind that day...) going to, I don't know, maybe 150dB (remember that this is a logarithmic scale, thus there is a limit, no matter how much energy you have at your disposal). Imagine now that instead of seating there at the press conference (which stays some miles from the shuttle), you decide to broke the security and seat right there near the shuttle. First problem: I think you can't find any microphone prepared to deal with that absolute volume without distortion. The microphone membrane will be fully stucked at one side with that king of sound pressure (maybe max. dc current in the sinal, with clipping at -0dBs when bass waves achives its peaks). Second problem: why you want to reproduce that kind of range, if your listener will go deaf exactly as you while recording there?
Okay, lets go back to the orchestra. Think about finger snap. If I where to record just finger snaps from only one hand during the whole track, I would have just microdynamics or microtransients (I think even a kick of drum can be classified as microtransient). If a recording engeneer were going to record a whole track with just fingers snaps from only one hand, where he would like to put the sinal within the CD dynamic range? I think that he wants to put it away from the bottom noise. Therefore, the snap peak is going to be near the full output (-0dBs, this is an electronic measure, not mechanical measure of volume). I think. While the real background is silent (at a well accousticall isolated studio), the inhereated electronic noise will be at the bottom, a long "distance" (volume) away from the snap minimum value (I don't know, maybe -10dBs). At that level, DAC and amplifier are working at full output, but with no huge dynamic range. How the listener gets an acceptable volume? He uses the volume attenuator knob, I think.
So you say, where is the orchestra? Think about a violin solo during a track. Know think about the whole orchestra (I mean 50 instruments) going at their full potential. Now we are talking about macrodynamics or macrotransients. What the recording engineer can do about that? He is able to close micing every instrument getting acceptable volume levels right at their side and mixing eveything at a huge mixing console. But imagine instead that he wants to use only to microphones at a cross pattern to get the stereo image and then recording the sinal direct to two tracks. He is going to have a violin solo at, I don't know, maybe 40 dB (at the mic position, not at the musician ears). During the same track, he is going to have a full output orchestra 120 dB. That means a 80dB dynamic range.
Wait! Now I see why a CD must have a huge dynamic range, you say. Okay, CD's have approximately 96dB (?) and that's why is so difficult to record an orchestra. Your violin is going to be at -90dBs, very close to the inherited electronic noise (of the whole chain, not just the recorded by the media related to microphones self-noise of the membrane (huge membranes are better to decrease that noise, condenser microphones better, very low noise) and preamplifiers, but also from DAC and amplifier. Your potential client, that guy that buy your CD is going to increase the volume, hearing not only the violin, but also your inherited eletronic noise. During the track, music is going stronger and your electronic chain goes to full output (-0dBs) with the orchestra 120dB momentum. Your listener gets deaf and tries to decrease the volume knob. I think that's why SACD improves on CD, because it has 120dB (?) dynamic range and your lowest signal gets more distance from the bottom electronic inherited noise.
Okay, okay, I undestood that. But why the recordings I have of an orchestra do not oscilate so much with my rig? Two things, I presume.
First, engineers know that problem and control the preamplifier volume knob on the fly (presume very difficult to do during the recording unless the engineer knows very well the maestro and the music he is recording) OR they let the preamplifier untouched and compress the signal during mastering (their only concern during recording is to avoid clipping at the orchestra absotute peak; they might have a clue by previous recordings with same orchestra composition or when they are fine tuning instruments). The first option is an analog compression of the dynamic range. The second one is a digital compression of the dynamic range. They put the 120 dB at -0dBs at the media and the 40dB violin at, I don't know, -50dBs, with digital computation (is this going to affect the signal resolution? I don't really know, but it sure affects the dynamics). Now your lowest recorded volume are going to be away from the inherited noise (right there at the bottom of the reproduced dynamic range), but your are not going to hear the real macro transient or macro dynamics. At your ear, sound may be going from 85dB at the violin solo to 125dB (amplifier at full output here) during the whole orchestra momentum.
Second, your amplifier is not prepared to deal with this raw amount of macro transients. So you say, is Spritzer correct then? I think people trying to compensate that compresion build amplifiers capable of huge headroom. Than that -0dbs to -50dBs dynamic range is sort of "amplified" again by a factor, let`s say to 40dB to 120dB. The problem is, I think, that while -dBs is an absolute measure of the electronic signal, I think there is no way to "inform" the amplifier (an standard dynamic range "amplification" factor) that it should be from 40dB to 120dB instead of going from 40dB to 130dB (without digital compression, but clipping the amplifier) or from 85dB to 125dB instead of 85dB to 135dB (hardly clipping I think at this volume, but the volume attenuator brings everything down here, ie, noise, lowest signal and highest signal), as I asked before...
Caution, here is where my comprehension gets more uncertain: I think that SACD deals with that using a 1bit variable scale instead of 24bits linear pcm discrete levels. Then the dynamic range is not limited by the amount of data you can store, but by the DAC chip swing. And you are able to increase the frequency sample because you are storing just one bit at each sample. If a lot of 0 are continously registered, signal is going down, if we have several 1`s continously, signal is going up. Initialize the dac standard volume and then the signal digital path will be adding 0 to go -dBs down until it reachs the right level (or adding 1 until it increase to -dBs correct level). Much better than having a discrete 24bits scale of -dBs. But, how that lot of 0's (or 1's) one after another do not interfere in signal frequency response? Because SACD is working with a sample much higher then the audible spectrum, I guess... I would love to understang that, really.
Please, I am just speculating. I would like to hear from engineers if all that is correct. Help us to understand!
p.s.: I think 2 Volts RMS is the maximum output power of a DAC when the digital signal is marked at -0dBs. During the playback the output is ranging from near zero (still electronic noise from the recorded, reproduced and added in/for circuit chain). Well, XLR balanced might have 4 Volts RMS, and might add less distortion as it has common noise reduction with opposite phases, but that's another whole problem (is there perfect noise reduction? phases are perfectly amplified within their paths?...)
p.s.: There is always a bottle neck in dynamic range. If it is not the media, it is the microphone membrane. If it not the microphone preamplifier during the recording, it is the amplifier during reproduction. Summ this with electronic noise and we will never have electronic reproduction faithfull to reality. But I see no problem with that. Try to listen to a flute and a saxophone in Manhattan and you will hear better the sax, although a lot of detail is being lost because there is a lot of background noise (bus, car, people etc.), but still there is music to be heard. And I think that's why we like to go to acoustically isolated concert halls with lots of internal diffusion to hear an orchestra details.
Go back to electronic reproduction. Imagine that you want to record at Cape Canaveral the space shuttle going to the International Space Station. You want to record those massive solid fuel tanks getting burned to beat the gravitational force. You are going to have a quiet place (okay, imagine that you don't have wind that day...) going to, I don't know, maybe 150dB (remember that this is a logarithmic scale, thus there is a limit, no matter how much energy you have at your disposal). Imagine now that instead of seating there at the press conference (which stays some miles from the shuttle), you decide to broke the security and seat right there near the shuttle. First problem: I think you can't find any microphone prepared to deal with that absolute volume without distortion. The microphone membrane will be fully stucked at one side with that king of sound pressure (maybe max. dc current in the sinal, with clipping at -0dBs when bass waves achives its peaks). Second problem: why you want to reproduce that kind of range, if your listener will go deaf exactly as you while recording there?
Okay, lets go back to the orchestra. Think about finger snap. If I where to record just finger snaps from only one hand during the whole track, I would have just microdynamics or microtransients (I think even a kick of drum can be classified as microtransient). If a recording engeneer were going to record a whole track with just fingers snaps from only one hand, where he would like to put the sinal within the CD dynamic range? I think that he wants to put it away from the bottom noise. Therefore, the snap peak is going to be near the full output (-0dBs, this is an electronic measure, not mechanical measure of volume). I think. While the real background is silent (at a well accousticall isolated studio), the inhereated electronic noise will be at the bottom, a long "distance" (volume) away from the snap minimum value (I don't know, maybe -10dBs). At that level, DAC and amplifier are working at full output, but with no huge dynamic range. How the listener gets an acceptable volume? He uses the volume attenuator knob, I think.
So you say, where is the orchestra? Think about a violin solo during a track. Know think about the whole orchestra (I mean 50 instruments) going at their full potential. Now we are talking about macrodynamics or macrotransients. What the recording engineer can do about that? He is able to close micing every instrument getting acceptable volume levels right at their side and mixing eveything at a huge mixing console. But imagine instead that he wants to use only to microphones at a cross pattern to get the stereo image and then recording the sinal direct to two tracks. He is going to have a violin solo at, I don't know, maybe 40 dB (at the mic position, not at the musician ears). During the same track, he is going to have a full output orchestra 120 dB. That means a 80dB dynamic range.
Wait! Now I see why a CD must have a huge dynamic range, you say. Okay, CD's have approximately 96dB (?) and that's why is so difficult to record an orchestra. Your violin is going to be at -90dBs, very close to the inherited electronic noise (of the whole chain, not just the recorded by the media related to microphones self-noise of the membrane (huge membranes are better to decrease that noise, condenser microphones better, very low noise) and preamplifiers, but also from DAC and amplifier. Your potential client, that guy that buy your CD is going to increase the volume, hearing not only the violin, but also your inherited eletronic noise. During the track, music is going stronger and your electronic chain goes to full output (-0dBs) with the orchestra 120dB momentum. Your listener gets deaf and tries to decrease the volume knob. I think that's why SACD improves on CD, because it has 120dB (?) dynamic range and your lowest signal gets more distance from the bottom electronic inherited noise.
Okay, okay, I undestood that. But why the recordings I have of an orchestra do not oscilate so much with my rig? Two things, I presume.
First, engineers know that problem and control the preamplifier volume knob on the fly (presume very difficult to do during the recording unless the engineer knows very well the maestro and the music he is recording) OR they let the preamplifier untouched and compress the signal during mastering (their only concern during recording is to avoid clipping at the orchestra absotute peak; they might have a clue by previous recordings with same orchestra composition or when they are fine tuning instruments). The first option is an analog compression of the dynamic range. The second one is a digital compression of the dynamic range. They put the 120 dB at -0dBs at the media and the 40dB violin at, I don't know, -50dBs, with digital computation (is this going to affect the signal resolution? I don't really know, but it sure affects the dynamics). Now your lowest recorded volume are going to be away from the inherited noise (right there at the bottom of the reproduced dynamic range), but your are not going to hear the real macro transient or macro dynamics. At your ear, sound may be going from 85dB at the violin solo to 125dB (amplifier at full output here) during the whole orchestra momentum.
Second, your amplifier is not prepared to deal with this raw amount of macro transients. So you say, is Spritzer correct then? I think people trying to compensate that compresion build amplifiers capable of huge headroom. Than that -0dbs to -50dBs dynamic range is sort of "amplified" again by a factor, let`s say to 40dB to 120dB. The problem is, I think, that while -dBs is an absolute measure of the electronic signal, I think there is no way to "inform" the amplifier (an standard dynamic range "amplification" factor) that it should be from 40dB to 120dB instead of going from 40dB to 130dB (without digital compression, but clipping the amplifier) or from 85dB to 125dB instead of 85dB to 135dB (hardly clipping I think at this volume, but the volume attenuator brings everything down here, ie, noise, lowest signal and highest signal), as I asked before...
Caution, here is where my comprehension gets more uncertain: I think that SACD deals with that using a 1bit variable scale instead of 24bits linear pcm discrete levels. Then the dynamic range is not limited by the amount of data you can store, but by the DAC chip swing. And you are able to increase the frequency sample because you are storing just one bit at each sample. If a lot of 0 are continously registered, signal is going down, if we have several 1`s continously, signal is going up. Initialize the dac standard volume and then the signal digital path will be adding 0 to go -dBs down until it reachs the right level (or adding 1 until it increase to -dBs correct level). Much better than having a discrete 24bits scale of -dBs. But, how that lot of 0's (or 1's) one after another do not interfere in signal frequency response? Because SACD is working with a sample much higher then the audible spectrum, I guess... I would love to understang that, really.
Please, I am just speculating. I would like to hear from engineers if all that is correct. Help us to understand!
p.s.: I think 2 Volts RMS is the maximum output power of a DAC when the digital signal is marked at -0dBs. During the playback the output is ranging from near zero (still electronic noise from the recorded, reproduced and added in/for circuit chain). Well, XLR balanced might have 4 Volts RMS, and might add less distortion as it has common noise reduction with opposite phases, but that's another whole problem (is there perfect noise reduction? phases are perfectly amplified within their paths?...)
p.s.: There is always a bottle neck in dynamic range. If it is not the media, it is the microphone membrane. If it not the microphone preamplifier during the recording, it is the amplifier during reproduction. Summ this with electronic noise and we will never have electronic reproduction faithfull to reality. But I see no problem with that. Try to listen to a flute and a saxophone in Manhattan and you will hear better the sax, although a lot of detail is being lost because there is a lot of background noise (bus, car, people etc.), but still there is music to be heard. And I think that's why we like to go to acoustically isolated concert halls with lots of internal diffusion to hear an orchestra details.








