


















jgazal
500+ Head-Fier
- Joined
- Nov 28, 2006
- Posts
- 730
- Likes
- 136
This post was written to try to answer the following questions:
Since immersive audio is a broad subject, I believe it deserves its own thread.
Question 1
Fundamental
There would be something fundamentally wrong if all types off recordings suffered from such unique distortion. But each kind of recording has its own peculiar set of distortions.
Spatial distortion
Spatial distortion could refer to:
Even if we define spatial distortion as the difference in perception of space of a real sound versus a reproduced sound, chances are every recording format played on every system would suffer spatial imprecision varying by degree, as described below.
But do not interpret the word distortion in this post as negative alteration, because although varying by degree, they are not a "fatal" types of distortion, as recordings were made with full knowledge that the reproducing systems probably were not going to match the creative environment exactly. Perhaps with cheaper digital signal processing we have a chance to even both environments.
Recordings
As per item 1 you need to know how your recording was made and what level of spatial precision you want to achieve, because you need to know which kind of distortion you need to address.
A layman multimedia guide to Immersive Sound for the technically minded (Immersive Audio and Holophony)
Before you continue to read (and I don’t think anyone will read a post so long), a warning: the following description may not be scientifically and completely accurate, but may help to illustrate the restrictions of sound reproduction. Others more knowledgeable may chime in, filling in the gaps and correcting misconceptions.
First of all you need to know how your perception works.
How do you acoustically differentiate someone stroking a piano 440hz note from someone blowing an oboe and pressing its 440hz key?
It is because the emitted sound: a) has the fundamental frequency accompanied by different overtones, partials that are harmonic and inharmonic to that fundamental, resulting an unique timbre (frequency domain) and b) has an envelope with peculiar attack time and characteristics, decay, sustain, release and transients (time domain).
When you hear an acoustical sound source how can your brain can perceive its location (azimuth, elevation and distance)?
Your brain uses several cues, for instance:
A, B and C are mathematically described as a head related transfer function - HRTF.
So you may ask which kind of recording is able to preserve such cues (spatial information that allows to reconstruct a lifelike soundfield) or how to synthesize them accurately.
One possible answer to that question could be dummy head stereo recordings, made with microphone diaphragms placed were each eardrum should be in a human being (Michael Gerzon - Dummy Head Recording).
The following video from @Chesky Records contains a state of the art binaural recording (try to listen at least until the saxophonist plays around the dummy head).
Just post in this thread if you perceive the singer displacing his head while he sings and the saxophonist walking around you.
However, each human being has an idiosyncratic head related transfer function and the dummy head stays fixed, while your listener turn his/her head.
What happens when you play binaural recordings through headphones?
The cues from the dummy head HRTF and your own HRTF cues don’t match and as you turn your head cues remain the same and the 3D sound field collapses.
What happens when you play binaural recordings through loudspeakers without a pillow or a mattress between the transducers?
Imagine a sound source placed to the left of a dummy head in an anechoic chamber and that, for didactic reasons, a very short pulse, coming from that sound source is fired into the chamber and arrives at the dummy head diaphragms. It will arrive first at its left diaphragm and after and lower in its right diaphragm. End of it. Only two pulses recorded because it is an anechoic chamber with fully absorptive walls. One intended for your left ear and the other for your right ear.
When you playback such pulse in your listening room, first the left loudspeaker fires the pulse into your listening room, it arrives before at your left eardrum, but also after and lower at your right eardrum. When the right speaker fires the pulse (the second arrival at the right dummy head diaphragm), it arrives first at you right ear and after and lower at your left ear.
So you were supposed to receive just two pulses, but you end receiving four pulses. If you now give up the idea of very short pulse and think about sounds, you can see that there is an acoustic crosstalk distortion intrinsically related to loudspeakers playback.
Since the pinna filtering from the dummy head fired into the listening room and interact with its acoustics, even not attempting to tackle acoustic crosstalk, there is a tonal coloration, that engineers try to compensate to make such recording more compatible with loudspeakers playback:
To make things worse there are early reflections boundaries in typical listening rooms. Early reflections arrive closely enough at your eardrum to confuse your brain. More “phantom pulses” or distortions that you have in the time domain. A short video explaining room acoustics:
There is also one more variable, which is speaker directivity. One concise explanation:
A rather long video, but Anthony Grimani, while talking at Home Theater Geek by Scott Wilkinson about room acoustics, gives a good explanation about speaker directivity (around 30:00):
Higher or lower speaker directivity may be preferred according to your aim.
Finally, the sum of two HRTF filterings (the dummy head and yours) may also introduce comb filtering distortions (additive and destructive interactions of sound waves).
With "binaural recordings to headphones" and "binaural recordings to loudspeakers" resulting no benefits, what could be an alternative?
Try something easier than a dummy head, such as ORTF microphone pattern:
For didactic reasons I will avoid going deeper into diaphragm pick up directivity and the myriad of microphone placing angles that one could use in a recording like this (for further details have a look at The Stereo Image - John Atkinson - stereophile.com).
So for the sake of simplicity, think about such ORTF pattern, as depicted above: just two diaphragms spaced at the average size of an human head so you can skip mixing and record direct to the final audio file.
Spectral cues are gone. Some recording engineers place foam disks between the microphones to keep the ILD closer to what would happen with human heads.
An example:
What happens when you play such “ORTF direct to audio file” with loudspeakers? You still have an acoustic crosstalk, but you have the illusion that the sound source is between the loudspeakers and at your left.
What happens when you play such “ORTF direct to audio file” with headphones? You don’t have acoustic crosstalk distortion, but ILD and ITD cues from the microphone arrangement don’t match your HRTF and as you turn your head cues remain the same and the horizontal stage collapses.
Are there more alternatives?
Yes, there are several. Some are:
Going the DSP brute force route to binauralization and to cancel (or avoid) crosstalk
Before whe start talking about DSP, you may want to grasp how they work mathematically and one fundamental concept to do that is the Furrier transform. I haven’t found better explanations than the ones made by Grant Sanderson (YouTube channel 3blue1brown):
A. The crosstalk cancellation route of binaural masters
So what Professor Edgar Choueiri advocates?
Use binaural recordings and play them back with his Bacch crosstalk cancellation algorithm (his processor also measures a binaural room impulse response to enhance his filter and use headtracking and interpolation to relieve head movement range restrictions one would have otherwise).
Dummy head HRTF used in the binaural recording and your own HRTF don’t match, but the interaction between speakers/room and your head and torso “sum” (filter) your own HRTF.
The “sum” (combined filtering) of two HRTF filterings may also introduce distortions (maybe negligible unless you want absolute localisation/spatial precision?).
Stereo recording with natural ILD and ITD, like the ORTF discribed above, render an acceptable 180 degrees horizontal sound stage. Read about the concept of proximity in the Bacch q&a Professor Choueiri has in the 3d3a of Princeton website.
Must watch videos of Professor Choueiri explaining crosstalk, his crosstalk cancellation filter and his flagship product:
Professor Choueiri explaining sound cues, binaural synthesis, headphone reproduction, ambisonics, wave field synthesis, among others concepts:
B. The crosstalk avoidance binauralization route
B.1 The crosstalk avoidance binauralization with headphones
And what you can do with DSPs like the Smyth Research Realiser A16?
Such processing circumvent the difficulty in acquiring an HRTF (or head related impulse response - HRIR) by measuring the user binaural room impulse responses - BRIR (or also personal room impulse response - PRIR, when you want to say that it refers to the unique BRIR of the listener) that also includes the playback room acoustic signature.
So after you measure a PRIR, the Realiser processor convolves the inputs with such PRIR, apply a filter to take out the effects of wearing the headphones you have chosen, add electronic/digital crossfeed and dynamically adjust cues (headtracking plus interpolation) with headphones playback to emulate/mimic virtual speakers like you would hear in the measured room, with the measured speaker(s), in the measured coordinates. Bad room acoustics will result bad acoustics in the emulation.
But you can avoid the addition of electronic/digital crossfeed to emulate what beaforming or a crosstalk cancellation algorithm would do with real speakers (see also here and here). This feature is interesting to playback binaural recordings, particularly those made with microphones in your own head (or here).
The Realiser A16 also allows equalization in the time domain (the latter is very useful to tame bass overhigh).
Add tactile/haptic transducers and you feel bone conducting bass not affected by the acoustics of your listening room. Note also that the power requirements to feed the headphone cavity are lower than feeding your listening room (thanks to brilliant @JimL11 for elaborating the power concept here) and that the intermodulation distortion characteristics of the speakers amplifier may then be substituted by those from the headphone amplifier (potentially lower IMD).
In the following (must hear) podcast interview (in English), Stephen Smyth explains concepts of acoustics, psychoacoustics and the features and compromises of the Realiser A16, like bass management, PRIR measurement, personalization of BRIRs, etc.
He also goes further and describes the lack of absolute neutral reference for headphones and the convinience of virtualizing a room with state of the art acoustics, for instance “A New Laboratory for Evaluating Multichannel Audio Components and Systems at R&D Group, Harman International Industries Inc.” with your own PRIR and HPEQ for counter-filtering your own headphones (@Tyll Hertsens, a method that personalizes room/pinnae and pinnae/headphones idiosyncratic coupling/filtering and keeps the acoustic basis for Harman Listening Target Curve).
Stephen Smyth at Canjam SoCal 2018 introduces the Realiser A16 (thanks to innerfidelity hosted by @Tyll Hertsens):
Stephen Smyth once again, but now introducing the legacy Realiser A8:
Is there a caveat? An small one but still yes, visual cues and sound cues interact and there is neuroplasticity:
Kaushik Sunder, while talking about immersive sound at Home Theater Geek by Scott Wilkinson, mentions how we learn since our childhood to analyze our very own HRTF and that such analyses is a constant learning process as we grow older with pinnae getting larger. But he also mentions the short term effects of neuroplasticity at 32:00:
Let’s hope Smyth Research can integrate the Realiser A16 to virtual headsets displaying stereoscopic photographs of measured rooms for visual training purpose and virtual reality.
B.1 The crosstalk avoidance binauralization with an phased array of transducers
So what is binaural beamforming?
It is not crosstalk cancellation but the clever use of a vertical phased array of transducers to control sound directivity resulting a similar effect.
One interesting description of binaural beamforming (continuation from @sander99 post above):
Peter Otto interview about binaural beamforming at Home Theater Geek by Scott Wilkinson:
Unfortunately the Yarra product does not offer a method to acquire a PRIR. So you can enjoy binaural recordings and stereo recordings with natural ILD and ITD. But you will not experience precise localization without inserting some personalized PRIR or HRTF.
Living in a world with (or without) crosstalk
If you want to think about the interactions between the way the content is recorded and the playback rig and environment and read other very long post, visit this thread: To crossfeed or not to crossfeed? That is the question...
Question 2
I find this question somehow harder.
You already know mixing engineers place sound sources between speakers with level differences. Some may also use ITD in conjunction and that helps with a better rendering when you use binaural beamforming or crosstalk cancellation with loudspeakers playback.
Recordings with coincident microphones direct to the final audio file incorporate early reflections and reverberation in a given venue spot.
Instruments recorded with closed microphones in several tracks and then mixed with other two tracks or digital processing that incorporate early reflections and reverberation in a given venue spot may theoretically give a sense of depth with two loudspeakers playback. But what is the level ratio between those tracks?
Can you mix them keeping the same ratio one would have with a binaural recording alone?
But not treating early reflections and bass acoustic problems in the playback room may also null any intelligibility of such depth you could theoretically convey.
I am curious to know how the processors that increase soundstage depth, that @bigshot mentioned here, work. An example would be the Illusonic Immersive Audio Processor, from Switzerland, a company that also provides the upmiximg algorithm in the Realiser A16, which extracts direct sound, early reflections and diffuse field in the original content and plays them separately over different loudspeakers:
Anyway, without a binaural recording and crosstalk cancellation (or binaural beamforming), playing back plain vanilla stereo recordings, you could only hear an impression (and probably a wrong one) of elevation by chance, in other words, if some distortion downstream is similar to your very own pinna spectral filtering. With multichannel you can try the method @bigshot describes here.
Going further in the sound science forum.
The following threads are also illustrative of concepts involved in the questions raised:
A) Accuracy is subjective (importance of how content is produced);
B) How do we hear height in a recording with earphones (the role of spectral cues);
C) Are binaural recordings higher quality than normal ones? (someone knowledgeable recommended books you want to read);
D) About SQ (rooms and speakers variations)
E) Correcting for soundstage? (the thread where this post started)
F) The DSP Rolling & How-To Thread (excellent thread about DSP started and edited by @Strangelove424)
To read more about the topics:
P.s.: I cannot thank @pinnahertz enough for all the knowledge he shares!
I see a new product being advertised and I was wondering about your take on it. I'm driven to post in this forum because "tube magic" is mentioned four times on the product description page and it seemed hokey. Based on my reading, it seems that more scientific explanations prevail here than elsewhere.
The company claims their new amp "corrects the fundamental spatial distortion in recordings" and "increases the width of the soundstage beyond that of the speaker placement." At the push of a button, an extra 30 degrees of soundstage can be recreated.
Question 1: Is there a fundamental spatial distortion in recordings?
Question 2: What is happening to my ears when (if) I experience depth or width to a recording? I believe that I do experience a soundstage effect that differs between headphones, but I'm at a loss to describe what is happening to the audio or to my perception of the audio. It is similar to the difference I hear between open back and closed back headphones.
Since immersive audio is a broad subject, I believe it deserves its own thread.
Question 1
Fundamental
There would be something fundamentally wrong if all types off recordings suffered from such unique distortion. But each kind of recording has its own peculiar set of distortions.
Spatial distortion
Spatial distortion could refer to:
a) what makes stereo recordings played back with loudspeakers different from stereo recordings played back with headphones;
OR
B) what makes our perception while listening to real sound sources different from listening virtual sound sources reproduced via electro-acoustical transducers.
OR
B) what makes our perception while listening to real sound sources different from listening virtual sound sources reproduced via electro-acoustical transducers.
Even if we define spatial distortion as the difference in perception of space of a real sound versus a reproduced sound, chances are every recording format played on every system would suffer spatial imprecision varying by degree, as described below.
But do not interpret the word distortion in this post as negative alteration, because although varying by degree, they are not a "fatal" types of distortion, as recordings were made with full knowledge that the reproducing systems probably were not going to match the creative environment exactly. Perhaps with cheaper digital signal processing we have a chance to even both environments.
Recordings
As per item 1 you need to know how your recording was made and what level of spatial precision you want to achieve, because you need to know which kind of distortion you need to address.
A layman multimedia guide to Immersive Sound for the technically minded (Immersive Audio and Holophony)
Before you continue to read (and I don’t think anyone will read a post so long), a warning: the following description may not be scientifically and completely accurate, but may help to illustrate the restrictions of sound reproduction. Others more knowledgeable may chime in, filling in the gaps and correcting misconceptions.
First of all you need to know how your perception works.
How do you acoustically differentiate someone stroking a piano 440hz note from someone blowing an oboe and pressing its 440hz key?
It is because the emitted sound: a) has the fundamental frequency accompanied by different overtones, partials that are harmonic and inharmonic to that fundamental, resulting an unique timbre (frequency domain) and b) has an envelope with peculiar attack time and characteristics, decay, sustain, release and transients (time domain).
When you hear an acoustical sound source how can your brain can perceive its location (azimuth, elevation and distance)?
Your brain uses several cues, for instance:
A) interaural time difference - for instance sound coming from your left will arrive first at your left ear and a bit after at your right ear;
B) interaural level difference - for instance sound coming from your left will arrive with higher level than at your right ear;
C) spectral cues - sound coming from above or below the horizontal plane that cross your ears will probably have not only a fundamental frequency a complex set of partials and then your outer ear (pinna) and your torso will change part of those frequencies in a very peculiar pattern related to the shape of your pinna and the size of your torso;
Sound localization - Wikipedia
- For frequencies below 1000 Hz, mainly ITDs are evaluated (phase delays), for frequencies above 1500 Hz mainly IIDs are evaluated. Between 1000 Hz and 1500 Hz there is a transition zone, where both mechanisms play a role.
C) spectral cues - sound coming from above or below the horizontal plane that cross your ears will probably have not only a fundamental frequency a complex set of partials and then your outer ear (pinna) and your torso will change part of those frequencies in a very peculiar pattern related to the shape of your pinna and the size of your torso;
D) head movements - each time you make a tiny movement with your head you change the cues and your brain track those changes according to its head position to solve ambiguous cues;
E) level ratio between direct sound and reverberation - for instance distant objects will have lower ratio and near sources will have higher ratio;
F) visual cues - yes visual cues and sound localization cues interact in the long and the short term;
G) etc.
A, B and C are mathematically described as a head related transfer function - HRTF.
Advanced “watch it later” - if you want to learn more about psychoacoustics and particularly about the precedent effect and neuroplasticity, watch the following brilliant lectures from Chris Brown (MITOpenCourseWare, Sensory Systems, Fall 2013, published on 2014):
So you may ask which kind of recording is able to preserve such cues (spatial information that allows to reconstruct a lifelike soundfield) or how to synthesize them accurately.
One possible answer to that question could be dummy head stereo recordings, made with microphone diaphragms placed were each eardrum should be in a human being (Michael Gerzon - Dummy Head Recording).
The following video from @Chesky Records contains a state of the art binaural recording (try to listen at least until the saxophonist plays around the dummy head).
Try to listen with loudspeakers in the very near field at more and less +10 and -10 degrees apart and with two pillows one in front of your nose in the median plane and the other at the top of your head to avoid ceiling reflections (or get an IPad Air with stereo speakers, touch your nose in the screen and direct the loudspeakers sound towards your ears with the palm of your hands; your own head will shadow the crosstalk).
Chesky Records
Just post in this thread if you perceive the singer displacing his head while he sings and the saxophonist walking around you.
However, each human being has an idiosyncratic head related transfer function and the dummy head stays fixed, while your listener turn his/her head.
What happens when you play binaural recordings through headphones?
The cues from the dummy head HRTF and your own HRTF cues don’t match and as you turn your head cues remain the same and the 3D sound field collapses.
What happens when you play binaural recordings through loudspeakers without a pillow or a mattress between the transducers?
Imagine a sound source placed to the left of a dummy head in an anechoic chamber and that, for didactic reasons, a very short pulse, coming from that sound source is fired into the chamber and arrives at the dummy head diaphragms. It will arrive first at its left diaphragm and after and lower in its right diaphragm. End of it. Only two pulses recorded because it is an anechoic chamber with fully absorptive walls. One intended for your left ear and the other for your right ear.
When you playback such pulse in your listening room, first the left loudspeaker fires the pulse into your listening room, it arrives before at your left eardrum, but also after and lower at your right eardrum. When the right speaker fires the pulse (the second arrival at the right dummy head diaphragm), it arrives first at you right ear and after and lower at your left ear.
So you were supposed to receive just two pulses, but you end receiving four pulses. If you now give up the idea of very short pulse and think about sounds, you can see that there is an acoustic crosstalk distortion intrinsically related to loudspeakers playback.
Since the pinna filtering from the dummy head fired into the listening room and interact with its acoustics, even not attempting to tackle acoustic crosstalk, there is a tonal coloration, that engineers try to compensate to make such recording more compatible with loudspeakers playback:
Some previous reporting has seemed to indicate the "+" is related to filters developed by Professor Edgar Choueiri of the 3-D Audio and Applied Acoustics (3D3A) Laboratory at Princeton University.
This is not the case. The "+" indicates that the EQ changes due to the pinna effects on the tonal character imparted on the sound has been restored to neutral EQ using carefully chosen compensation curves.
Read more at https://www.innerfidelity.com/conte...dphone-demonstration-disc#IzEmD8iz8lEHGfSo.99
To make things worse there are early reflections boundaries in typical listening rooms. Early reflections arrive closely enough at your eardrum to confuse your brain. More “phantom pulses” or distortions that you have in the time domain. A short video explaining room acoustics:
There is also one more variable, which is speaker directivity. One concise explanation:
The whole thing makes perfect sense to me. It is consistant with what I know about vibration sources and wave propagation.
For example one thing that is usefull to know is that a vibration source that is considerably larger than the wavelength it produces will beam, a vibration source that is considerably smaller than the wavelength it produces will spread the waves.
A vertical long and narrow (compared to the wavelength it is producing) shaped vibration source will beam vertical and spread horizontal. With the inverse square law you refer to the rate of propagation loss as a function of the distance?
That law only holds for spheric shaped wavefronts from point sources. For example line sources have cylindrical shaped wavefronts and have propagation loss linear with the distance.
Vertical line sources beam in the vertical and have wide dispersion in the horizontal.
An horizontal array of small drivers all playing in phase acts as a horizontal line array and will in the horizontal have a narrower dispersion pattern (getting narrower with higher frequencies).
By manipulating the relative phase between the drivers the dispersion pattern can be made narrower (or wider), and the direction can be changed.
For example delaying the inner drivers compared to the outer drivers will further narrow the beam. (The classic Quad ESL63 electrostatic loudspeaker with concentric circular stators uses the opposite principle: to decrease directivity the outer rings receive a delayed signal). (...)
A rather long video, but Anthony Grimani, while talking at Home Theater Geek by Scott Wilkinson about room acoustics, gives a good explanation about speaker directivity (around 30:00):
Higher or lower speaker directivity may be preferred according to your aim.
Finally, the sum of two HRTF filterings (the dummy head and yours) may also introduce comb filtering distortions (additive and destructive interactions of sound waves).
With "binaural recordings to headphones" and "binaural recordings to loudspeakers" resulting no benefits, what could be an alternative?
Try something easier than a dummy head, such as ORTF microphone pattern:
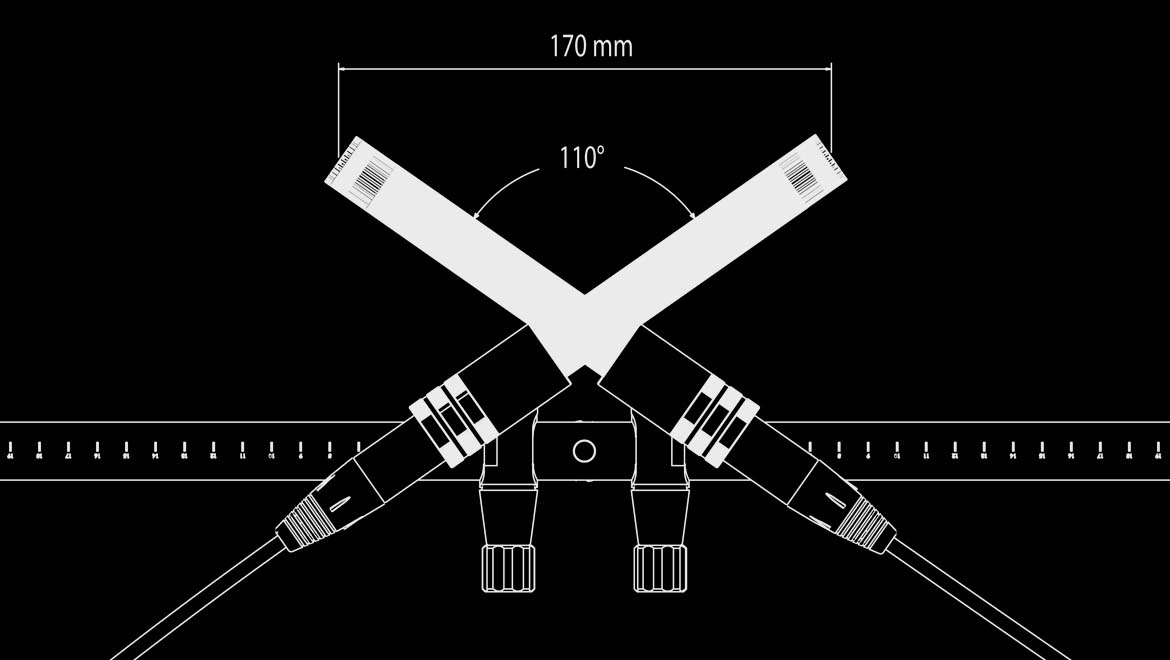
For didactic reasons I will avoid going deeper into diaphragm pick up directivity and the myriad of microphone placing angles that one could use in a recording like this (for further details have a look at The Stereo Image - John Atkinson - stereophile.com).
So for the sake of simplicity, think about such ORTF pattern, as depicted above: just two diaphragms spaced at the average size of an human head so you can skip mixing and record direct to the final audio file.
Spectral cues are gone. Some recording engineers place foam disks between the microphones to keep the ILD closer to what would happen with human heads.
An example:
What happens when you play such “ORTF direct to audio file” with loudspeakers? You still have an acoustic crosstalk, but you have the illusion that the sound source is between the loudspeakers and at your left.
What happens when you play such “ORTF direct to audio file” with headphones? You don’t have acoustic crosstalk distortion, but ILD and ITD cues from the microphone arrangement don’t match your HRTF and as you turn your head cues remain the same and the horizontal stage collapses.
Are there more alternatives?
Yes, there are several. Some are:
A) Close microphones to stereo mix.
Record each track with a microphone close to the sound source and mix all of them into two channels using ILD to place them in the horizontal soundstage (panning - pan pot).
Reverberations from the recording venue need to be captured in other two tracks from an microphone arrangement that allow then preservation of such cues an that is mixed into those two channels.
The ILD of each instrument track (more precisely the level such track will have the right and left channel) and the ratio between instrument tracks and reverberation tracks is chosen by the engineer and do not necessarily match what a dummy head would register if all instruments were playing together around it during the recording.
You still have acoustic crosstalk when playing back with speakers and soundstage will collapse with headphones.
In this case, if the ILD/ITD levels are unnatural, when using headphones, as @71 dB advocates, adding electronic crossfeed may avoid the unnatural perception that sound sources are only at the left diaphragm, at the right diaphragm and right in the center:
How many recordings have unnatural ILD and ITD? IDK.
B) Mix multichannel with level panning.
@pinnahertz describes some historical facts about multichannel recording here.
Even with more channels, there is still some level of acoustic crosstalk when playing back through loudspeakers in regular room, unless all sounds/tracks are hard-panned.
You just can’t convey proximity as one would in reality (a bee flying closely your head; or the saxophonist from Chesky recording above if the speakers are placed further than the distance the saxophonist was playing when he was recorded...).
C) Record with Ambisonics.
This is interesting as the recording is made with a tetrahedron microphone (or an eigenmike, as close as possible to measure a sound field at a single point) and the spherical harmonics are decoded to be played back into an arrangement of speakers around the listener.
So with Ambisonics the spatial effect is not derived from two microphones but at from at least four microphones that encode height spatial information (The Principles of Quadraphonic Recording Part Two: The Vertical Element By Michael Gerzon) and the user HRTF is acoustically filtered at playback.
There are two problems.
The first one is that you need a decoder.
The second one is that at high frequencies the math proves that you need too many loudspeakers to be practical:
Although the spherical harmonics seem more mathematically elegant, I still do not figured out how acoustic crosstalk in listening rooms - or instead the auralization with headphones without adding electronic crosstalk - affects the possibility of conveying sound fields and proximity, neither if crosstalk cancellation in high order ambisonics ready listening rooms with high directivity loudspeakers is feasible.
Let’s hope third order ambisonics, eigenmikes and clever use of psychoacoustics are good enough! See item 2.C of the post #2 below or here to have an idea of such path.
If ambisonics spherical harmonics decoding already solves acoustic crosstalk at at low and medium frequencies, then the only potential negative variables would be the number of channels for high frequencies and the listening room early reflections. That would be in fact an advantage of convolving a high density/resolution HRTF/HRIR (when you can decode to an arbitrary higher number of playback channels) instead of interpolated low density/resolution HRIR or BRIR (of sixteen discreet virtual sources for instance), when binauralizing ambisonics over headphones. Current, state of the art, example of High-Order-Ambisonics-to-binaural rendering DSP:
Problem is that, currently, HRTF are acoustically measured in anechoic chambers, a costly and time consuming procedure:
In the following video Professor Choueiri demonstration of a high density/resolution HRTF acquisition through acoustical measurements:
That is one of the reasons why this path may benefit from easier ways to acquire high density/resolution HRTF such as capturing biometrics and searching for close enough HRTF in databases:
Fascinating research in 3D Audio and Applied Acoustics (3D3A) Laboratory at Princeton University:
D) Wavefield synthesis.
This one is also interesting, but complex as the transducers tend to infinity (just kidding, but there are more transducers). You will need to find details somewhere else, like here. And it is obviously costly!
E) Pure object based.
Record each sound source at its own track and don’t mix them before distribution. Just tag them with metadata describing their coordinates.
Let the digital player at the listening room mix all tracks considering the measured high density/resolution HRTF of the listener (or lower density/resolution with better interpolation algorithms) and room modeling to calculate room reflections and reverberation (“Accurate real-time early reflections and reverb calculations based on user-controlled room geometry and a wide range of wall materials” from bacch-dsp binaural synthesis).
Playback with crosstalk cancellation (or binaural beamforming with an horizontal array of transducers such as the yarra sound bar; more details forward in this post) or use headphones with head-tracking without adding electronic crossfeed.
This is perfect for the realms of virtual environments for video games in which the user interact with the graphic and narrative context determining the future states of sound objects.
What are the problems with a pure object based approach? As we have just seen, it is costly and time consuming to measure the HRTF from the listener. It is computational intensive to mix those tracks and calculate room reflections and reverberation. You just can’t calculate complex rooms. So you miss the acoustic signature of really unique venues.
Atmos and other hybrid multichannel object based codecs use also beds to preserve some cues. But such beds and the panning of objects between speakers also introduce the distortions from the chains before mentioned (unless it also relies in spherical harmonics computation?).
Reverberations from the recording venue need to be captured in other two tracks from an microphone arrangement that allow then preservation of such cues an that is mixed into those two channels.
The ILD of each instrument track (more precisely the level such track will have the right and left channel) and the ratio between instrument tracks and reverberation tracks is chosen by the engineer and do not necessarily match what a dummy head would register if all instruments were playing together around it during the recording.
You still have acoustic crosstalk when playing back with speakers and soundstage will collapse with headphones.
In this case, if the ILD/ITD levels are unnatural, when using headphones, as @71 dB advocates, adding electronic crossfeed may avoid the unnatural perception that sound sources are only at the left diaphragm, at the right diaphragm and right in the center:
(...). I have given the "magic" number 98 %.
A lot of recordings of that era were recorded hard panned so that "half" of the instruments were on the left and "half" on the right and perhaps some in the middle. Example: Dave Brubeck: Jazz Impressions of Eurasia.
How many recordings have unnatural ILD and ITD? IDK.
B) Mix multichannel with level panning.
In stereo, only sources intended to emanate from the exact speaker locations are present correctly, as they are hard-panned and you localize the speaker and the source in the same place. Every other position depends on phantom imaging, which in stereo, in order to work, your head must be precisely equidistant between and from both speakers. That makes the listening window for stereo a single point, which is itself imperfect, because every phantom image has acoustic crosstalk built in. Multichannel reduces that problem by placing an actual speaker at the primary source locations. And more channels works even better.
Credit: @pinnahertz
@pinnahertz describes some historical facts about multichannel recording here.
Even with more channels, there is still some level of acoustic crosstalk when playing back through loudspeakers in regular room, unless all sounds/tracks are hard-panned.

You just can’t convey proximity as one would in reality (a bee flying closely your head; or the saxophonist from Chesky recording above if the speakers are placed further than the distance the saxophonist was playing when he was recorded...).
C) Record with Ambisonics.
This is interesting as the recording is made with a tetrahedron microphone (or an eigenmike, as close as possible to measure a sound field at a single point) and the spherical harmonics are decoded to be played back into an arrangement of speakers around the listener.
So with Ambisonics the spatial effect is not derived from two microphones but at from at least four microphones that encode height spatial information (The Principles of Quadraphonic Recording Part Two: The Vertical Element By Michael Gerzon) and the user HRTF is acoustically filtered at playback.
There are two problems.
The first one is that you need a decoder.
The second one is that at high frequencies the math proves that you need too many loudspeakers to be practical:
Unfortunately, arguments from information theory can be used to show that to recreate a sound field over a two-metre diameter listening area for frequencies up to 20kHz, one would need 400,000 channels and loudspeakers. These would occupy 8GHz of bandwidth, equivalent to the space used up by 1,000 625-line television channels!
Surround-sound psychoacoustics - Michael Gerzon

If ambisonics spherical harmonics decoding already solves acoustic crosstalk at at low and medium frequencies, then the only potential negative variables would be the number of channels for high frequencies and the listening room early reflections. That would be in fact an advantage of convolving a high density/resolution HRTF/HRIR (when you can decode to an arbitrary higher number of playback channels) instead of interpolated low density/resolution HRIR or BRIR (of sixteen discreet virtual sources for instance), when binauralizing ambisonics over headphones. Current, state of the art, example of High-Order-Ambisonics-to-binaural rendering DSP:
Problem is that, currently, HRTF are acoustically measured in anechoic chambers, a costly and time consuming procedure:

The Quietest Place on Earth?
Veritasium - Can silence actually drive you crazy?
In the following video Professor Choueiri demonstration of a high density/resolution HRTF acquisition through acoustical measurements:
That is one of the reasons why this path may benefit from easier ways to acquire high density/resolution HRTF such as capturing biometrics and searching for close enough HRTF in databases:
all in all it's only mysterious because we're lacking the tools to look at your head and say "you need that sound", but the mechanisms for the most part are well understood and modeled with success by a few smart people.
3D audio is the secret to HoloLens' convincing holograms
(...)
The HoloLens audio system replicates the way the human brain processes sounds. "[Spatial sound] is what we experience on a daily basis," says Johnston. "We're always listening and locating sounds around us; our brains are constantly interpreting and processing sounds through our ears and positioning those sounds in the world around us."
The brain relies on a set of aural cues to locate a sound source with precision. If you're standing on the street, for instance, you would spot an oncoming bus on your right based on the way its sound reaches your ears. It would enter the ear closest to the vehicle a little quicker than the one farther from it, on the left. It would also be louder in one ear than the other based on proximity. These cues help you pinpoint the object's location. But there's another physical factor that impacts the way sounds are perceived.
Before a sound wave enters a person's ear canals, it interacts with the outer ears, the head and even the neck. The shape, size and position of the human anatomy add a unique imprint to each sound. The effect, called Head-Related Transfer Function (HRTF), makes everyone hear sounds a little differently.
These subtle differences make up the most crucial part of a spatial-sound experience. For the aural illusion to work, all the cues need to be generated with precision. "A one-size-fits-all [solution] or some kind of generic filter does not satisfy around one-half of the population of the Earth," says Tashev. "For the [mixed reality experience to work], we had to find a way to generate your personal hearing."
His team started by collecting reams of data in the Microsoft Research lab. They captured the HRTFs of hundreds of people to build their aural profiles. The acoustic measurements, coupled with precise 3D scans of the subjects' heads, collectively built a wide range of options for HoloLens. A quick and discreet calibration matches the spatial hearing of the device user to the profile that comes closest to his or hers.
(...)
A method for efficiently calculating head-related transfer functions directly from head scan point clouds
Authors: Sridhar, R., Choueiri, E. Y.
Publication: 143rd Convention of the Audio Engineering Society (AES 143)
Date: October 8, 2017
A method is developed for efficiently calculating head-related transfer functions (HRTFs) directly from head scan point clouds of a subject using a database of HRTFs, and corresponding head scans, of many subjects. Consumer applications require HRTFs be estimated accurately and efficiently, but existing methods do not simultaneously meet these requirements. The presented method uses efficient matrix multiplications to compute HRTFs from spherical harmonic representations of head scan point clouds that may be obtained from consumer-grade cameras. The method was applied to a database of only 23 subjects, and while calculated interaural time difference errors are found to be above estimated perceptual thresholds for some spatial directions, HRTF spectral distortions up to 6 kHz fall below perceptual thresholds for most directions.
Errata:
- In section 3.2 on page 4, the last sentence of the first paragraph should read “…and simple geometrical models of the head…”.
(...)
In the past, the way to acquire unique HRTF profiles was to fit miniature microphones in your ears. You would have to remain completely still inside an anechoic chamber for an extended period of time to take the necessary measurements. Thanks to dedicated computer modelling, those days are finally over. Using their smartphone’s camera, users will be able to scan themselves, gathering sufficient data for IDA Audio and Genelec to accurately 3D model and then create the unique HRTF filter set for personal rendering of 3D audio. Users will also be able to choose to undertake the scan with a designated third party if preferred. Based on years of comprehensive research, IDA Audio’s modelling algorithms provide precision that matches Genelec’s dedication to the accuracy and acoustic transparency of reproduced sound.
(...)
Fascinating research in 3D Audio and Applied Acoustics (3D3A) Laboratory at Princeton University:
Models for evaluating navigational techniques for higher-order ambisonics - Joseph G. Tylka and Edgar Y. Choueiri
Virtual navigation of three-dimensional higher-order ambisonics sound fields (i.e., sound fields that have been decomposed into spherical harmonics) enables a listener to explore an acoustic space and experience a spatially-accurate perception of the sound field. Applications of sound field navigation may be found in virtual-reality reproductions of real-world spaces. For example, to reproduce an orchestral performance in virtual reality, navigation of an acoustic recording of the performance may yield superior spatial and tonal fidelity compared to that produced through acoustic simulation of the performance. Navigation of acoustic recordings may also be preferable when reproducing real-world spaces for which computer modeling of complex wave-phenomena and room characteristics may be too computationally intensive for real-time playback and interaction.
Recently, several navigational techniques for higher-order ambisonics have been developed, all of which may degrade localization information and induce spectral coloration. The severity of such penalties needs to be investigated and quantified in order to both compare existing navigational techniques and develop novel ones. Although subjective testing is the most direct method of evaluating and comparing navigational techniques, such tests are often lengthy and costly, which motivates the use of objective metrics that enable quick assessments of navigational techniques.
This one is also interesting, but complex as the transducers tend to infinity (just kidding, but there are more transducers). You will need to find details somewhere else, like here. And it is obviously costly!
E) Pure object based.
Record each sound source at its own track and don’t mix them before distribution. Just tag them with metadata describing their coordinates.
Let the digital player at the listening room mix all tracks considering the measured high density/resolution HRTF of the listener (or lower density/resolution with better interpolation algorithms) and room modeling to calculate room reflections and reverberation (“Accurate real-time early reflections and reverb calculations based on user-controlled room geometry and a wide range of wall materials” from bacch-dsp binaural synthesis).
Playback with crosstalk cancellation (or binaural beamforming with an horizontal array of transducers such as the yarra sound bar; more details forward in this post) or use headphones with head-tracking without adding electronic crossfeed.
This is perfect for the realms of virtual environments for video games in which the user interact with the graphic and narrative context determining the future states of sound objects.
What are the problems with a pure object based approach? As we have just seen, it is costly and time consuming to measure the HRTF from the listener. It is computational intensive to mix those tracks and calculate room reflections and reverberation. You just can’t calculate complex rooms. So you miss the acoustic signature of really unique venues.
Atmos and other hybrid multichannel object based codecs use also beds to preserve some cues. But such beds and the panning of objects between speakers also introduce the distortions from the chains before mentioned (unless it also relies in spherical harmonics computation?).
Going the DSP brute force route to binauralization and to cancel (or avoid) crosstalk
Before whe start talking about DSP, you may want to grasp how they work mathematically and one fundamental concept to do that is the Furrier transform. I haven’t found better explanations than the ones made by Grant Sanderson (YouTube channel 3blue1brown):
A. The crosstalk cancellation route of binaural masters
So what Professor Edgar Choueiri advocates?
Use binaural recordings and play them back with his Bacch crosstalk cancellation algorithm (his processor also measures a binaural room impulse response to enhance his filter and use headtracking and interpolation to relieve head movement range restrictions one would have otherwise).
Before we continue with Bacch filter, a few notes about room impulse response and a recovery of speaker directivity.
There is a room impulse response for each (Length x Width x Height) coordinates of a given room. A RIR can be measured by playing a chirp sweep from 20hz to 20khz from a source in a given coordinate. The microphone will capture early reflections and reverberation at another given coordinate. Change those source and microphone coordinates/spots and RIR is going to be different. Room enhancement DSPs use RIR to compute equalization for a given listening spot (Digital Room Equalisation - Michael Gerzon), but if you want even bass response across more listening spots then you probably need more subwoofers (Subwoofers: optimum number and locations - Todd Welti). A BRIR is also dependent of the coordinates in which it is measured (and looking angle!). But instead you measure with two microphones at the same time at the entrance of a human head or dummy head. That is one of the reasons why you need to capture one BRIR for each listening spot you want the crosstalk canceled filter to work. Such BRIR integrates not only the combined acoustic signature of loudspeakers and room, but also the HRTF of the dummy head or the human wearing the microphones.
Here an speaker with higher directivity may improve the performance of the algorithm.
There is a room impulse response for each (Length x Width x Height) coordinates of a given room. A RIR can be measured by playing a chirp sweep from 20hz to 20khz from a source in a given coordinate. The microphone will capture early reflections and reverberation at another given coordinate. Change those source and microphone coordinates/spots and RIR is going to be different. Room enhancement DSPs use RIR to compute equalization for a given listening spot (Digital Room Equalisation - Michael Gerzon), but if you want even bass response across more listening spots then you probably need more subwoofers (Subwoofers: optimum number and locations - Todd Welti). A BRIR is also dependent of the coordinates in which it is measured (and looking angle!). But instead you measure with two microphones at the same time at the entrance of a human head or dummy head. That is one of the reasons why you need to capture one BRIR for each listening spot you want the crosstalk canceled filter to work. Such BRIR integrates not only the combined acoustic signature of loudspeakers and room, but also the HRTF of the dummy head or the human wearing the microphones.
Here an speaker with higher directivity may improve the performance of the algorithm.
Dummy head HRTF used in the binaural recording and your own HRTF don’t match, but the interaction between speakers/room and your head and torso “sum” (filter) your own HRTF.
The “sum” (combined filtering) of two HRTF filterings may also introduce distortions (maybe negligible unless you want absolute localisation/spatial precision?).
Stereo recording with natural ILD and ITD, like the ORTF discribed above, render an acceptable 180 degrees horizontal sound stage. Read about the concept of proximity in the Bacch q&a Professor Choueiri has in the 3d3a of Princeton website.
Must watch videos of Professor Choueiri explaining crosstalk, his crosstalk cancellation filter and his flagship product:
Professor Choueiri explaining sound cues, binaural synthesis, headphone reproduction, ambisonics, wave field synthesis, among others concepts:
B. The crosstalk avoidance binauralization route
B.1 The crosstalk avoidance binauralization with headphones
And what you can do with DSPs like the Smyth Research Realiser A16?
Such processing circumvent the difficulty in acquiring an HRTF (or head related impulse response - HRIR) by measuring the user binaural room impulse responses - BRIR (or also personal room impulse response - PRIR, when you want to say that it refers to the unique BRIR of the listener) that also includes the playback room acoustic signature.
Before we continue with the Realiser processor, a few notes about personalization of BRIRs. Smyth Research Exchange site will allow you to use your PRIR made with a single tweeter to personalize BRIRs made by other users in rooms you may be interested to acquire. So the performance will be better than just use that BRIR that may poorly match yours.
So after you measure a PRIR, the Realiser processor convolves the inputs with such PRIR, apply a filter to take out the effects of wearing the headphones you have chosen, add electronic/digital crossfeed and dynamically adjust cues (headtracking plus interpolation) with headphones playback to emulate/mimic virtual speakers like you would hear in the measured room, with the measured speaker(s), in the measured coordinates. Bad room acoustics will result bad acoustics in the emulation.
But you can avoid the addition of electronic/digital crossfeed to emulate what beaforming or a crosstalk cancellation algorithm would do with real speakers (see also here and here). This feature is interesting to playback binaural recordings, particularly those made with microphones in your own head (or here).
The Realiser A16 also allows equalization in the time domain (the latter is very useful to tame bass overhigh).
Add tactile/haptic transducers and you feel bone conducting bass not affected by the acoustics of your listening room. Note also that the power requirements to feed the headphone cavity are lower than feeding your listening room (thanks to brilliant @JimL11 for elaborating the power concept here) and that the intermodulation distortion characteristics of the speakers amplifier may then be substituted by those from the headphone amplifier (potentially lower IMD).
In the following (must hear) podcast interview (in English), Stephen Smyth explains concepts of acoustics, psychoacoustics and the features and compromises of the Realiser A16, like bass management, PRIR measurement, personalization of BRIRs, etc.
He also goes further and describes the lack of absolute neutral reference for headphones and the convinience of virtualizing a room with state of the art acoustics, for instance “A New Laboratory for Evaluating Multichannel Audio Components and Systems at R&D Group, Harman International Industries Inc.” with your own PRIR and HPEQ for counter-filtering your own headphones (@Tyll Hertsens, a method that personalizes room/pinnae and pinnae/headphones idiosyncratic coupling/filtering and keeps the acoustic basis for Harman Listening Target Curve).
Stephen Smyth at Canjam SoCal 2018 introduces the Realiser A16 (thanks to innerfidelity hosted by @Tyll Hertsens):
Stephen Smyth once again, but now introducing the legacy Realiser A8:
Is there a caveat? An small one but still yes, visual cues and sound cues interact and there is neuroplasticity:
VIRTUALISATION PROBLEMS
Conflicting aural and visual cues
Even if headphone virtualisation is acoustically accurate, it can still cause confusion if the aural and visual impressions conflict. [8] If the likely source of a sound cannot be identified visually, it may be perceived as originating from behind the listener, irrespective of auditory cues to the contrary. Dynamic head-tracking strengthens the auditory cues considerably, but may not fully resolve the confusion, particularly if sounds appear to originate in free space. Simple visible markers, such as paper speakers placed at the apparent source positions, can help to resolve the remaining audio-visual perceptual conflicts. Generally the problems associated with conflicting cues become less important as users learn to trust their ears.
http://www.smyth-research.com/articles_files/SVSAES.pdf
Kaushik Sunder, while talking about immersive sound at Home Theater Geek by Scott Wilkinson, mentions how we learn since our childhood to analyze our very own HRTF and that such analyses is a constant learning process as we grow older with pinnae getting larger. But he also mentions the short term effects of neuroplasticity at 32:00:
Let’s hope Smyth Research can integrate the Realiser A16 to virtual headsets displaying stereoscopic photographs of measured rooms for visual training purpose and virtual reality.
B.1 The crosstalk avoidance binauralization with an phased array of transducers
So what is binaural beamforming?
It is not crosstalk cancellation but the clever use of a vertical phased array of transducers to control sound directivity resulting a similar effect.
One interesting description of binaural beamforming (continuation from @sander99 post above):
(...) A beam can be shifted [Edit: I mean the angle can be shifted] to the left or the right by relative delaying drivers from one side to the other.
More independent beams can be created by superimposing the required combinations of driver signals upon eachother.
(With 'one combination of driver signals' I meant the 12 driver signals for one beam. So to get more beams more combinations (plural) are added together.) (Each driver contributes to all the beams).
By the way: the Yarra only beams in the horizontal, in the vertical it has wide dispersion (narrowing down with increasing frequency of course).
Low frequencies are harder to beam in narrow beams. This is consistant with the fact that in the video with the three different sources over three beams they used mainly mid and high frequencies probably to avoid low frequencies "crossing over".
For the normal intended use of the Yarra this should not cause a problem because the lower the frequency the less vital role it plays for localisation, so don't fear that the Yarra will sound equally thin as in that video.
Peter Otto interview about binaural beamforming at Home Theater Geek by Scott Wilkinson:
Unfortunately the Yarra product does not offer a method to acquire a PRIR. So you can enjoy binaural recordings and stereo recordings with natural ILD and ITD. But you will not experience precise localization without inserting some personalized PRIR or HRTF.
Living in a world with (or without) crosstalk
If you want to think about the interactions between the way the content is recorded and the playback rig and environment and read other very long post, visit this thread: To crossfeed or not to crossfeed? That is the question...
Question 2
I find this question somehow harder.
You already know mixing engineers place sound sources between speakers with level differences. Some may also use ITD in conjunction and that helps with a better rendering when you use binaural beamforming or crosstalk cancellation with loudspeakers playback.
Recordings with coincident microphones direct to the final audio file incorporate early reflections and reverberation in a given venue spot.
Instruments recorded with closed microphones in several tracks and then mixed with other two tracks or digital processing that incorporate early reflections and reverberation in a given venue spot may theoretically give a sense of depth with two loudspeakers playback. But what is the level ratio between those tracks?
Can you mix them keeping the same ratio one would have with a binaural recording alone?
But not treating early reflections and bass acoustic problems in the playback room may also null any intelligibility of such depth you could theoretically convey.
I am curious to know how the processors that increase soundstage depth, that @bigshot mentioned here, work. An example would be the Illusonic Immersive Audio Processor, from Switzerland, a company that also provides the upmiximg algorithm in the Realiser A16, which extracts direct sound, early reflections and diffuse field in the original content and plays them separately over different loudspeakers:
Here is a link to a video about it:
Anyway, without a binaural recording and crosstalk cancellation (or binaural beamforming), playing back plain vanilla stereo recordings, you could only hear an impression (and probably a wrong one) of elevation by chance, in other words, if some distortion downstream is similar to your very own pinna spectral filtering. With multichannel you can try the method @bigshot describes here.
Going further in the sound science forum.
The following threads are also illustrative of concepts involved in the questions raised:
A) Accuracy is subjective (importance of how content is produced);
B) How do we hear height in a recording with earphones (the role of spectral cues);
C) Are binaural recordings higher quality than normal ones? (someone knowledgeable recommended books you want to read);
D) About SQ (rooms and speakers variations)
E) Correcting for soundstage? (the thread where this post started)
F) The DSP Rolling & How-To Thread (excellent thread about DSP started and edited by @Strangelove424)
To read more about the topics:

Table of Contents
Contributors
Foreword
WIESLAW WOSZCZYK
Acknowledgements
Introduction
AGNIESZKA ROGINSKA AND PAUL GELUSO
1 Perception of Spatial Sound
ELIZABETH M. WENZEL, DURAND R. BEGAULT, AND MARTINE GODFROY-COOPER
Auditory Physiology
Human Sound Localization
Head-Related Transfer Functions (HRTFs) and Virtual Acoustics
Neural Plasticity in Sound Localization
Distance and Environmental Context Perception
Conclusion
2 History of 3D Sound
BRAXTON BOREN
Introduction
Prehistory
Ancient History
Space and Polyphony
Spatial Separation in the Renaissance
Spatial Innovations in Acoustic Music
3D Sound Technology
Technology and Spatial Music
Conclusions and Thoughts for the Future
3 Stereo
PAUL GELUSO
Stereo Systems4 Binaural Audio Through Headphones
Creating a Stereo Image
Stereo Enhancement
Summary
AGNIESZKA ROGINSKA
Headphone Reproduction
Binaural Sound Capture
HRTF Measurement
Binaural Synthesis
Inside-the-Head Locatedness
Advanced HRTF Techniques
Quality Assessment
Binaural Reproduction Methods
Headphone Equalization and Calibration
Conclusions
Appendix: Near Field
5 Binaural Audio Through Loudspeakers
EDGAR CHOUEIRI
Introduction
The Fundamental XTC Problem
Constant-Parameter Regularization
Frequency-Dependent Regularization
The Analytical BACCH Filter
Individualized BACCH Filters
Conclusions
Appendix A Derivation of the Optimal XTC Filter
Appendix B: Numerical Verification
6 Surround Sound
FRANCIS RUMSEY
The Evolution of Surround Sound
Surround Sound Formats
Surround Sound Delivery and Coding
Surround Sound Monitoring
Surround Sound Recording Techniques
Perceptual Evaluation
Predictive Models of Surround Sound Quality
7 Height Channels
SUNGYOUNG KIM
Background
Fundamental Psychoacoustics of Height-Channel Perception
Multichannel Reproduction Systems With Height Channels
Recording With Height Channels
Conclusion
8 Object-Based Audio
NICOLAS TSINGOS
Introduction
Spatial Representation and Rendering of Audio Objects
Advanced Metadata and Applications of Object-Based Representations
Managing Complexity of Object-Based Content
Audio Object Coding
Capturing Audio Objects
Tradeoffs of Object-Based Representations
Object-Based Loudness Estimation and Control
Object-Based Program Interchange and Delivery
Conclusion
9 Sound Field
ROZENN NICOL
Introduction
Development of the Sound Field
Higher Order Ambisonics (HOA)
Sound Field Synthesis
Sound Field Formats
Conclusion
Appendix A: Mathematics and Physics of Sound Field
Appendix B: Mathematical Derivation of W, X, Y, Z
Appendix C: The Optimal Number of Loudspeakers
10 Wave Field Synthesis
THOMAS SPORER, KARLHEINZ BRANDENBURG, SANDRA BRIX, AND CHRISTOPH
SLADECZEK
Motivation and History
Separation of Sound Objects and Room
WFS Reproduction: Challenges and Solutions
WFS With Elevation
Audio Metadata and WFS
Applications Based on WFS and Hybrid Schemes
WFS and Object-Based Sound Production
11 Applications of Extended Multichannel Techniques
BRETT LEONARD
Source Panning and Spreading
An Immersive Overhaul for Preexisting Content
Considerations in Mixing for Film and Games
Envelopment
Musings on Immersive Mixing
Index
https://www.routledge.com/Immersive...el-Audio/Roginska-Geluso/p/book/9781138900004
P.s.: I cannot thank @pinnahertz enough for all the knowledge he shares!
Attachments

Last edited:
 Perhaps he would change his opinion with RIR convolution reverbs instead of algorithmic reverbs that were available in his time?
Perhaps he would change his opinion with RIR convolution reverbs instead of algorithmic reverbs that were available in his time?