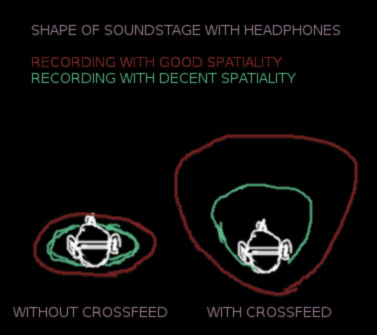
Even if the results often are as good as possible, Stereo has objective limitations and we think that there is room for significant improvement in both the playback and recording technologies/techniques.
I hope that you'll find this blog post on the subject interesting...
")
Flavio
https://www.dirac.com/dirac-blog/perfect-sound-system-with-3d-sound-reproduction
Sure I find Dirac Research work interesting.
I have been following “Dynamic 3D audio” and “Panorama Sound” algorithms:
This crazy audio software can make your smartphone sound like a Hi-Fi system.
I am sure you know Choueiri (Bacch) and Smyth (SVS) work and I bet you also know why Kyle Wiggers found Dirac’s “Panorama Sound” more impressive than “Dynamic 3D audio”.
As Professor Choueiri says, calculating personalized HRTF from anthropometric data was already done and the challenge know is to find less computational demanding methods to do so.
Dirac Research certainly has as much expertise to solve that problem as Qualcomm, Genelec/IDA, Princeton 3D3A lab team etc.
But the problem I believe will be critical after solving the personalization challenge is creating mixing engines that allow artists to mix for crosstalk free listening environments (headphone externalization devices, beamforming phased array of transducers and crosstalk cancellation algorithms) with the same artistic freedom they are used to with currently standard mixing (i.e. applying different reverberation for each steam).
Ultimately, I would like recording and mixing engineers to feel assured they can record with spot microphones and apply different types of reverberation for each steam and at the same time expand soundstage beyond the boundaries of two stereo loudspeakers and also allow vertical dimension with only two loudspeakers.
Finally, I would like to understand how Ambisonics downmixed to binaural for headphones differ from Ambisonics decoded for loudspeakers in a room. The crosstalk in the second environment makes my understanding fuzzy.
I have never listened to Ambisonics environment. When Professor Smyth describes his test of an Ambisonics 16 channels decoder in a 4.8.4 arrangement (bottom, central and top layers) he does not mentioned how acoustic crosstalk is managed in the binauralization algorithm. I bet the beta algorithm did not simulate acoustic crosstalk from contralateral channels.
And I would like to know how much
room reflections and acoustic crosstalk in real rooms affect the performance of Ambisonics. I believe in anechoic rooms spherical harmonics do not introduce crosstalk, the problem to me is reflections in a reverberant room.
In the end, any format relying in spherical harmonics and binauralization in the playback stage (for headphones and phased array of transducers) may be the most practical chain to create an universal rig that allows Virtual/augmented reality and playback of acoustic genres and popular genres. Professor Choueiri prefers to introduce binauralization before distribution with Binaural synthesis...
But recording and mixing engineers still find realistic rendering such as the one from sound field microphones (or binaural dummy head microphones) detracts creativity for popular genres.
I encourage people with strong mathematics and DSP skills to help them to achieve, with spherical harmonics formats (or binaural synthesis), the same artistic freedom they currently have when mixing standard stereo. And of course mono compatibility for radio broadcast.
Cheers!