Very cool. Inspired by folks reporting that the Smyth Realizer actually really does work well, I picked up a set of in-ear binaural mics a while back with the intent of doing very much what you describe above. Additionally I wanted to experiment with HRTFs and Ambiophonics-over-headphones which I think could be very interesting. I haven't had any time whatsoever to start down the road though.
I have had a fair bit of success with the DRC software (drc-fir.sourceforge.net) for speaker/room correction. You're correct that the two problems are rather different, but since DRC is parameter driven it may well be possible to hack together a workable config for phones. I was going to try starting there for lack of any other sophisticated filter generation package that I'm aware of.
I think the main question in my mind is how to figure out what the 'ideal' FR is for a headphone. My assumption is that it is not flat, and should compensate for the difference in HRTF between something firing straight into your ear from the side and something firing from ~30 degrees off center out front which is where most recordings will be eq'd for. I *think* the Smyth realizer process gets to more or less ignore this though, since it's measuring the effective HRTF in both cases, so they automatically cancel out of the problem. It seems viable to do something along the lines of measuring a speaker response from both positions to deduce the FR difference - it would be a bit more cumbersome and would probably involve correcting the speaker to begin with, but if my thought experiment is correct is should result in something resembling the desired target response..
Anyway, really interesting problem that I'm hoping to spend some time on, but probably won't have much free time until the fall.
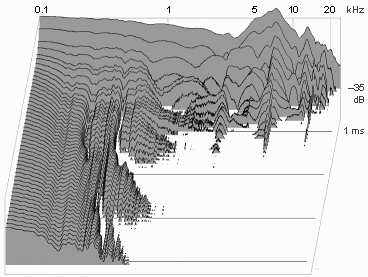
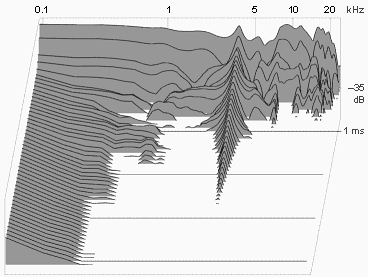
On a different topic, I was planning to pick up some closed cans for a system at work, and was thinking of the FA-003 or the Brainwavez equivalents. Based on your CSD results I'm reconsidering going down the T50RP route. I didn't really want to get sucked into modding, but the results look fairly promising.


















")
