I on the other hand would argue that as experience grows and the baseline widens, you are in a better position to anticipate how instruments will sound different depending on setting and how they are being played.
Surely, as your baseline widens, the range of instrument sounds that could be accurate also widens/increases and therefore, how do you know where in the baseline range is the actual sound intended on the recording, not to mention, what happens if your baseline is still not wide enough? For consumers it can rarely be wide enough and what happens is that they pick a sound within their baseline and compare to that, regardless of whether that’s the actual sound intended on the recording. So now they’re comparing different sound systems to their baseline (or choice within a baseline range) rather than to what is actually in the recording and therefore their judgement of “subjective fidelity” is nothing to do with fidelity but simply a preference that they’ve chosen. And also, it isn’t just “
depending on setting and how they’re being played” but also on how and where they’re mic’ed and how they’re processed and that leads us to:
And doesn't the sound engineer also have to make a subjective decision when mixing, as to what sounds "right" and what sounds "wrong"?; don't they need extensive experience of real live instuments' sound for that?
Well exactly, the sound engineer (and producer) make subjective decisions but how do you know what those subjective decisions were? Again, you are assuming what the “
real live instruments’ sound” is, and the goal is to achieve a recording which is “right” relative to that sound, but it is not! The aim is not a judgement of right or wrong relative to the original/real live instrument sound, it’s a judgement of “better” or “worse” and commonly or virtually always with rock and any of the popular genres, “better” actually means “more wrong” (less accurate to the actual sound that existed). In fact in many cases the difference is huge, the actual sound of say a drum kit in a studio is vastly different to the (manufactured) sound required in say Metal genres or virtually all electronic music and significantly different even to other types of rock and pop. Even in classical music it can be somewhat different.
While I can’t teach you all about recording and mixing in a single forum post, maybe this one example will help: All mixing desks (inc. software/virtual ones) feature a “Solo” button, which allows us to listen to an individual channel/instrument on it’s own. One thing we have to drill into students is not to spend much time applying processing (EQ, compression or whatever) in solo mode. The reason for this is that you can spend quite some time in solo mode, processing an individual instrument on it’s own to sound exactly “right” but then when you come out of solo mode and combine that instrument with all the other instruments in the mix, it no longer sounds “right”. So the bulk of the processing needs to be done out of solo mode (with the rest of the mix) and the result is that hopefully the instrument sounds “right” in the mix but probably “wrong” on it’s own (solo’ed)! And note again, that “right” and “wrong” in the above refers to closer to or further from what the engineer/producer wants, not more or less accurate to the sound that existed.
Indeed room acoustics matter a lot, but one has to sort the obvious room acoustic problems first before judging speakers.
But that is typically not possible or possible only to a very limited degree. Consumers typically cannot afford an acoustic designer or to loose a substantial percentage of their room volume to acoustic treatments.
And YMMV, but I am quite sensitive to poorly matched spikes between the left and right capsules. Swapping capsules as well as swapping channels makes it quite clear that it is a capsule matching issue, and it can vary a lot between different samples of the same model headphones.
Sure but there you have an obvious reference, the left capsule to the right capsule. But when comparing audio systems with a music recording you are comparing (as you rightly said) the performance of each system based on the subjective decisions of the engineer/producer, which you do not know. So your reference is to what you think it should sound like or what you would prefer it to sound like, not necessarily what it actually does sound like.
In the world of rock and pop music the now ubiquitous heavy-handed use of dynamic compression and autotune/pitch correction are obvious examples. Consumers want it, I **** hate it.
No you don’t, I can absolutely guarantee that if all the compression were removed, it would sound like utter crap and you would hate it. The audiophile community have been saying this for years but it’s just another example of BS invented by those who have little/no idea how recordings are created. Compression is a fundamental tool that allows rock/pop music to exist, it would not exist without it! Unlike an orchestra or established acoustic ensemble, a rock/pop band does not inherently work, a human voice cannot compete (balance) with a rock/pop drum kit or the guitars and the bass guitar does not compete with the lead guitar, etc. Rock/pop evolved in response to the recording technology which enabled it and compression along with EQ are the two most fundamental tools which enable it. The issue is not the use of compression (which is essential) but the over-application of it and that is not as “black and white” as it may appear because the judicious application of compression for one genre (or recording) could be a serious over-application on another or not enough in another. For example, the judicious application of compression for say a 1970’s or 1980’s rock or pop recording would be insufficient for the vast majority of electronic and other genres since the 1990’s but a very serious (very ‘heavy handed”) over-application for almost all classical music recordings. And incidentally, the over-application of compression was the biggest topic of conversation amongst engineers when I first stated getting into the business in 1992, at least a decade or two before the audiophile community even noticed it.
Occasionally I come across a very simple live recording done by a small venue, just one or two mics, without all the consumer-preferred processing, and it sounds so much better to my ears.
That is possible and sometimes it results in excellent recordings. However, it typically results is worse recordings, a recording that could have been better, although of course consumers won’t ever know that, because they don’t know enough about recording/mixing/mastering to realise and they obviously do not have a better recording of that event to compare. The problem with “purist” recording, just using a stereo pair or other minimalist mic’ing, is that you have no option to change anything. You have to get it perfect to start with and if you later hear something that could be better or that you didn’t notice at the time, there’s probably nothing you can do about it. Taking your example of sensitivity to slightly too much or too little reverb, let’s say the engineer or producer notices too little or too much reverb when back in the high quality studio environment after recording in say a church with a poor monitoring environment; with a stereo/minimalist mic’ed recording you’re stuffed, there’s nothing you can do about it. Compare this with more typical mic’ing, one or two close mic’s which will therefore pick up far more direct sound and relatively little or no reverb, in addition to a couple of far more distant “room” mics, which will pick up little or no direct sound and almost entirely the reflections/reverb. Back in the studio you mix all the mics together and can increase or decrease the amount of reverb by increasing or decreasing the balance of the room mics. And this is of course just one example, multi-mic’ing would also allow us to alter the balance, EQ or whatever of individual instruments or groups of instruments, if it wasn’t recorded or performed perfectly at the time. There’s disadvantages too, for example the close mics will record freqs and sounds that would not exist or would not be audible to any audience members (or to a simple stereo pair) and also there’s likely to be some amount of timing/phase issues, so processing will sometimes/often need to be applied to compensate. However, the advantages greatly outweigh the disadvantages, which is why “purist” labels in the past have either failed to compete or competed for a few recordings and then given up and switched multi-mic’ing.
I have often wondered whether that processing (autotune/pitch correction & dynamic compression in particular) is really something that consumers wanted, or whether they have been made to want it and have become so used to hearing it that way that they now insist on it themselves. But that's a different topic.
It is a different topic but it is what consumers want. Particularly for rock and pop genres, consumers would rather have a beautiful male or female lead vocalist that can’t sing in tune very well and therefore needs to be auto-tuned, than an ugly lead singer with such a good voice they do not need auto-tuning. Opera singers are a bit different, they still need to be attractive but not as young and attractive and they’ve had many years of very intensive training which not only gives them excellent intonation and note production but also teaches them to effectively create the same effect as audio compression, which is essential for the acoustic sound projection necessary in quite large venues (such as Opera Houses). Pop/Rock vocalists get almost none of this training, certainly not the decade or more of intensive formal training before they even stand a change of being a professional, and they don’t need much of it anyway, they have mic’s, sound systems and compressors!
but I for one wouldn’t mind paying a few extra $$ for an “audiophile” (hate that term) edition …
That is what some/many SACDs give you. A more heavily compressed CD layer compared to the DSD layer but that’s only with some SACDs, commonly it’s the same master on both layers. The vast majority of us engineers would want that as well, not SACD but a higher quality/less compressed alternative 16/44 “audiophile” version, but budget/time restrictions, especially these days won’t allow it.
G













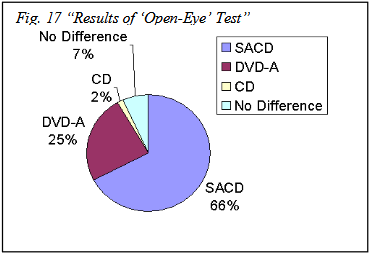







 But I guess you think the contrast I made here is a flawed one, which it is indeed. Sound engineers are also music lovers. Let me rephrase it as a disconnect between sound engineers on the one hand, and audiophile music lovers who aren't also sound engineers on the other hand.
But I guess you think the contrast I made here is a flawed one, which it is indeed. Sound engineers are also music lovers. Let me rephrase it as a disconnect between sound engineers on the one hand, and audiophile music lovers who aren't also sound engineers on the other hand.