

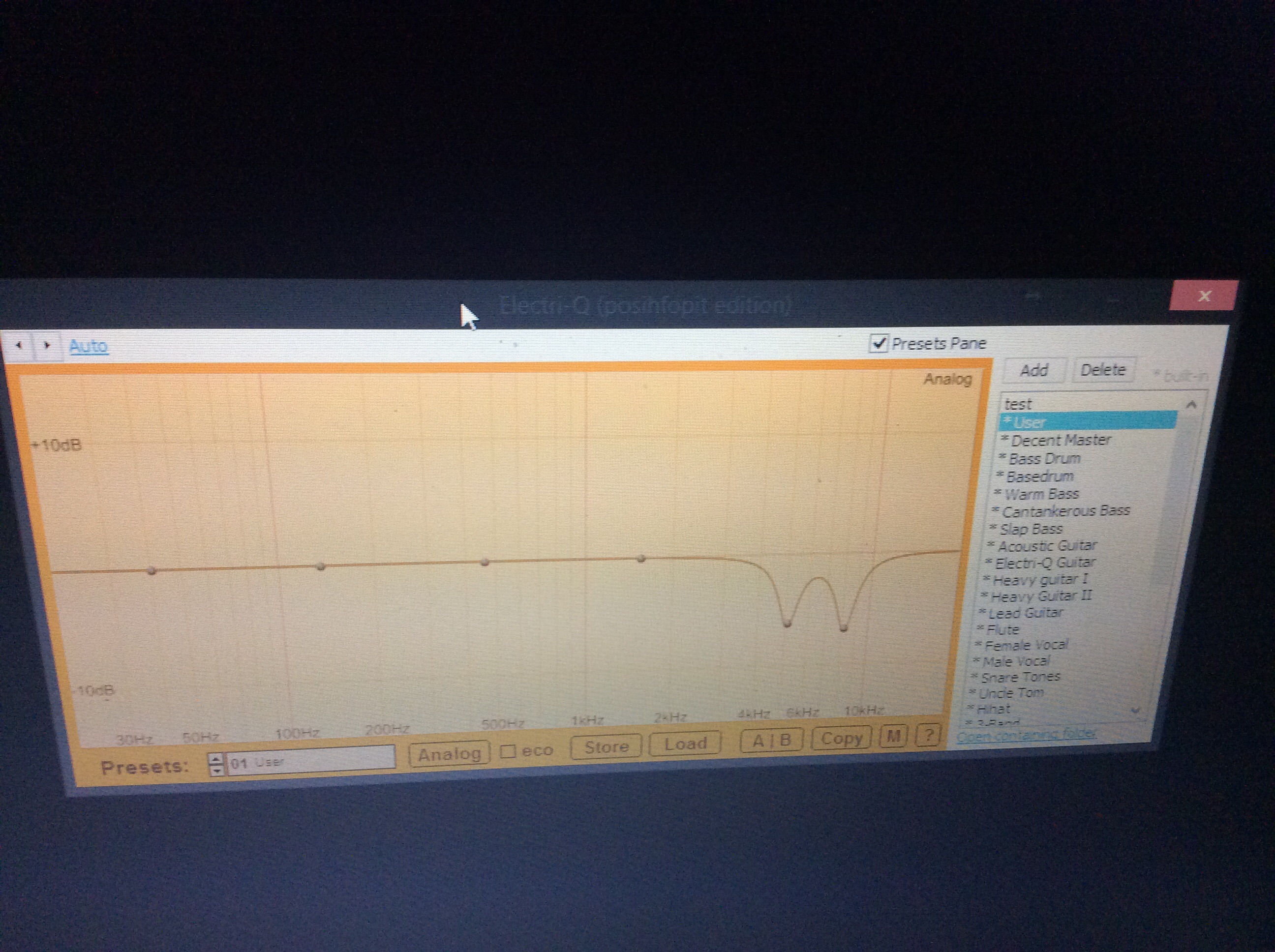
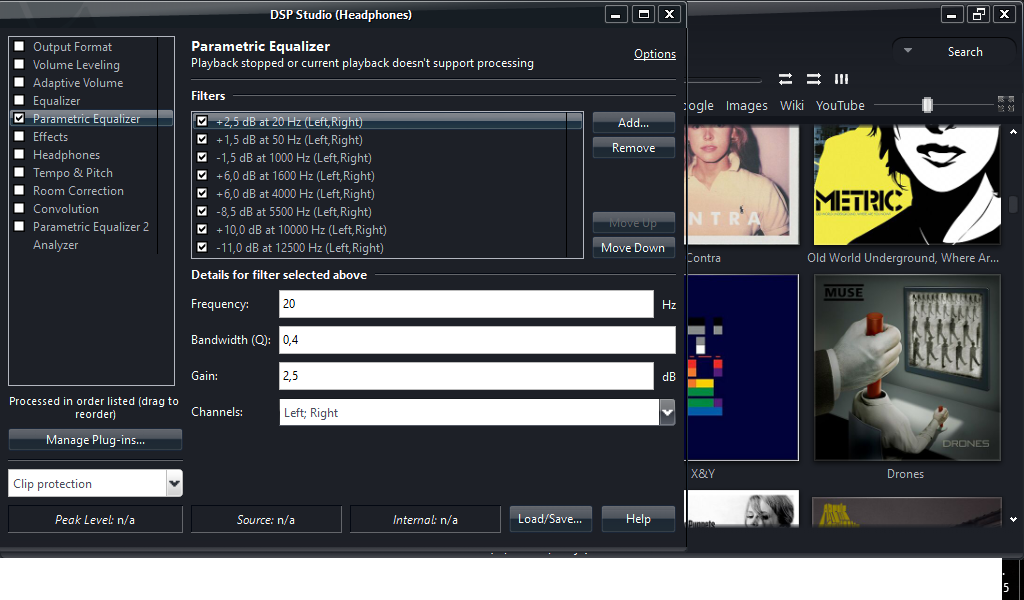



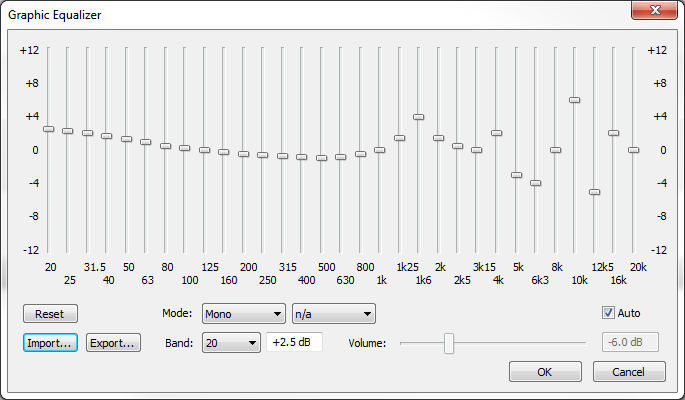

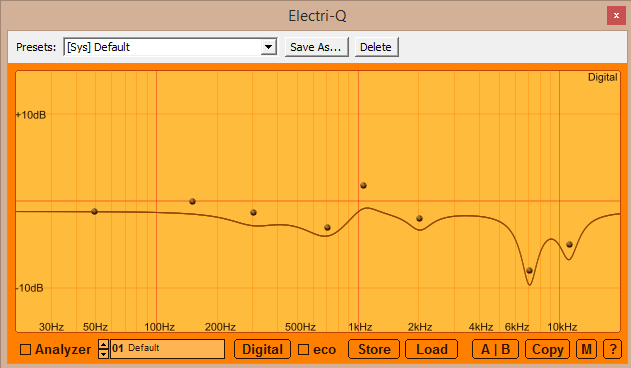






Argyris
Head-Fi's third most long-winded poster.
Quote:
There are other arguments that could have been made. If you read the entire exchange, you'll see that I kind of just blasted the guy, which I regretted as soon as I posted it. I didn't want to carry on the argument anymore since, as the web comic he posted illustrates, in the general scheme of things what we were arguing about isn't really very important. No need to fight. I guess his posts just rubbed me the wrong way.
Anyway, the idea of one frequency masking another is one of the fundamental principles of any lossy data compression algorithm. The encoder analyzes the waveform, works out which parts are unlikely to be missed, and pitches them. Of course it's not smart enough to work out which portions correspond, say, to the stiction of a bow on strings or other minute details. It also can't separate out individual instruments from the sum waveform. In other words, it's unaware of the actual audio realization of all the data it analyzes. All it can do is compare the amplitude of the various constituents of the signal, note where very quiet elements occur alongside very loud ones, and reduce the complexity of the signal by eliminating the quiet elements, thus reducing the file size. Of course encoders do a lot more than this, but this where the "lossy" aspect comes from, and where the idea of frequency masking is vindicated.
When a person says that they want to alter the characteristic of a headphone so that the mids don't cover the highs, they mean that the louder your mids are, less highs you are going to listen, because the louder the mids are, the quieter every other frequency is going to sound. Your perception of sounds adapts according to the sound pressure level, which not only the mids contribute to.
If you don't understand this it is no surprise you say what you do.
Also you acuse others of audiophile guesswork, but you seem to be quite eager to collect headphones without understanding the function and usefulness of equalizers.
There are other arguments that could have been made. If you read the entire exchange, you'll see that I kind of just blasted the guy, which I regretted as soon as I posted it. I didn't want to carry on the argument anymore since, as the web comic he posted illustrates, in the general scheme of things what we were arguing about isn't really very important. No need to fight. I guess his posts just rubbed me the wrong way.
Anyway, the idea of one frequency masking another is one of the fundamental principles of any lossy data compression algorithm. The encoder analyzes the waveform, works out which parts are unlikely to be missed, and pitches them. Of course it's not smart enough to work out which portions correspond, say, to the stiction of a bow on strings or other minute details. It also can't separate out individual instruments from the sum waveform. In other words, it's unaware of the actual audio realization of all the data it analyzes. All it can do is compare the amplitude of the various constituents of the signal, note where very quiet elements occur alongside very loud ones, and reduce the complexity of the signal by eliminating the quiet elements, thus reducing the file size. Of course encoders do a lot more than this, but this where the "lossy" aspect comes from, and where the idea of frequency masking is vindicated.


