@csglinux, in my opinion you kind of set the tone of this conversation. I've known
@pfzar for some time, and when I first started doing audio measurements he was immensely knowledgable and helpful. If you have a chance to discuss the research he and his colleagues have done (at least some of which you can find published in the AES library), I think you'll find the same about him.
I think part of the disconnect in this discussion is that you seem to have interpreted what was said in the video as an attack on FFT analysis. I thought
@Mr.Jacob's mention of Dr. Genuit's soup analogy (not to mention
the rest of the video discussion) was enough to make this clearer, but it seems I was wrong.
No, that's not what's needed here, because....
....that's simply not the case.
But that's not what was said. (Read the posts by
@Mr.Jacob,
@pfzar,
@arnaud, and
@castleofargh above.)
Regarding psychoacoustics, here's another very simple example (because when it comes to the subject of psychoacoustics, the only knowledge I have to draw on are the very simplest examples):
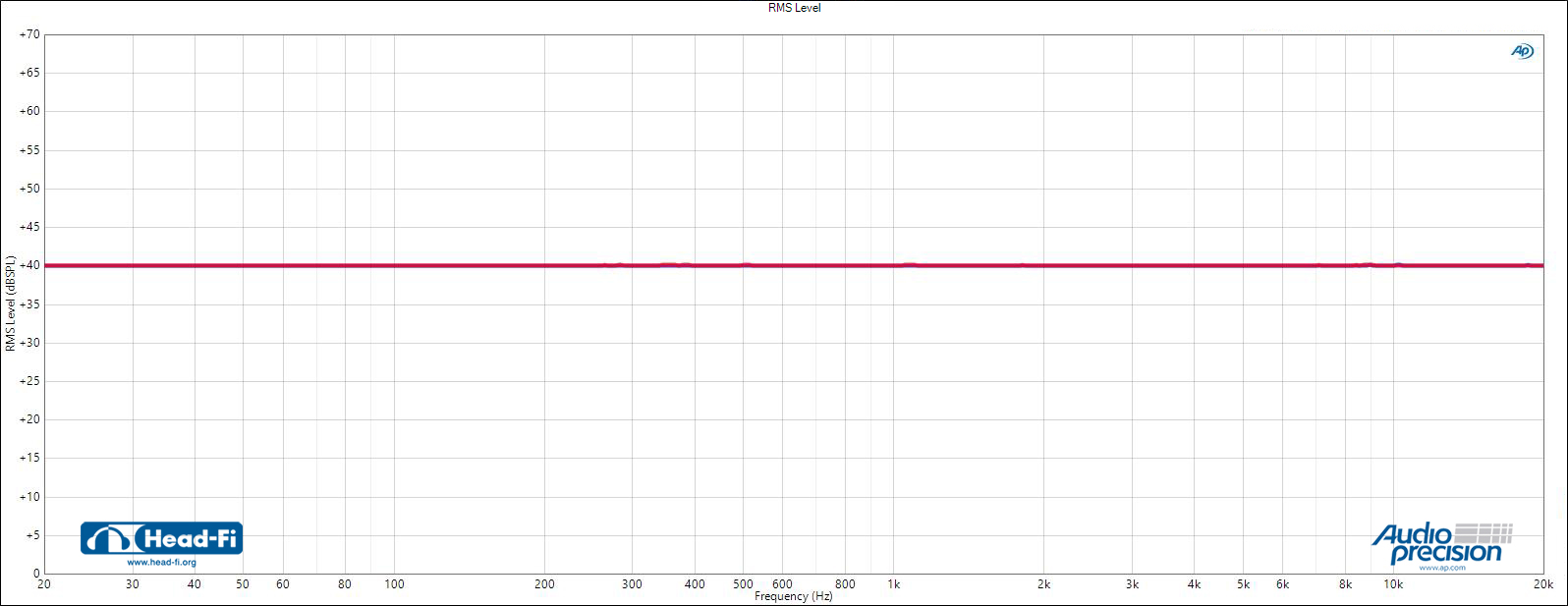
 Fig.1 (above) 40 dBSPL stepped frequency sweep
Fig.1 (above) 40 dBSPL stepped frequency sweep
That was just an analyzer loopback, but assume for the sake of example that Fig.1 represented an acoustical capture (through a linear measurement microphone) of a stepped frequency sweep. At any of the steps in that range, we know the measured level is 40 dBSPL.
However, what if the question we were trying to answer was
"Would human perception of that output be best represented by this measurement (in Fig.1 above)?"
The answer is "no."
In answering "no," would one be bashing FFT analysis? Of course not.
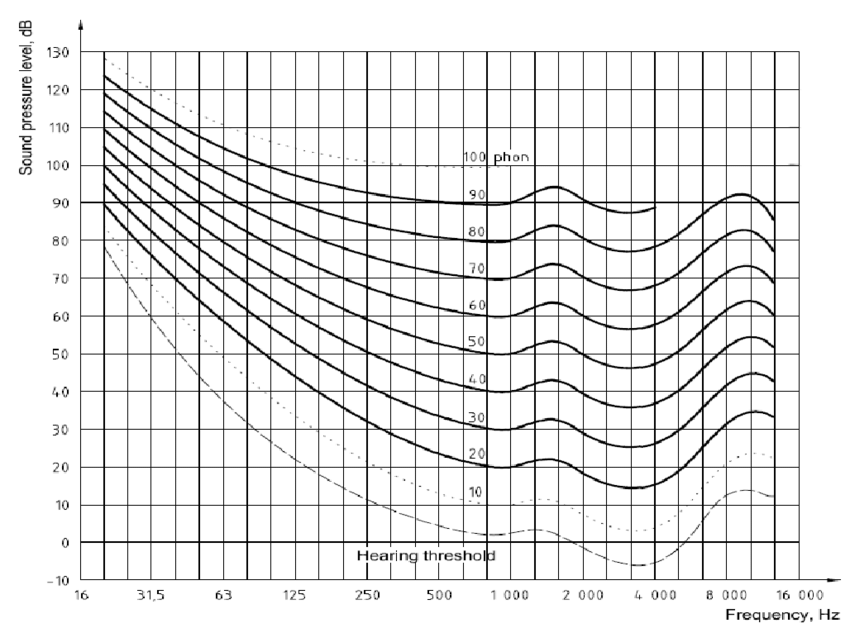
To help us better answer that simple question, there's a commonly referenced psychoacoustic measure that we use to represent perception of equal loudness that we commonly call the Fletcher-Munson Curve (but that has been modernized with equal loudness contours in ISO 226:2003 (shown below)):
 Fig.2 (above) Equal loudness contours (ISO 223:2003)
Fig.2 (above) Equal loudness contours (ISO 223:2003)
Because loudness is our brain's perception of sound pressure, then loudness is a psychoacoustic phenomenon -- so let's look at a psychoacoustic measure. Looking at the 40-phon curve in Fig.2, we can correlate the human perception of the output in Fig.1. The 40-phon curve shows us that to perceive a 20 Hz tone as equally loud as a 1 kHz tone at 40 dBSPL, that 20 Hz tone would need to be at a sound pressure level of 100 dBSPL. A 125 Hz tone would have to be 60 dBSPL to be perceived by a human as equally loud as a 1 kHz tone at 40 dBSPL. Etc.
So while Fig.1 would
not represent
human perception of the output (a 40 dBSPL stepped frequency sweep), perhaps an inverse of the 40-phon curve in Fig.2 (a psychoacoustic measure) would better represent human perception of that output. (
@pfzar,
@Mr.Jacob,
@arnaud, or anyone else more qualified, please correct me if I'm wrong or have oversimplified this.)
So is the measurement in Fig.1 wrong? No, it is what it is. But what it is
not is the best answer to the question
"How would a human perceive the output that generated the FFT-based measurement in Fig.1?"
And that's not bashing FFT analysis.
The phase information, and hopping back and forth between time and frequency domains, still would not yield the answer to the question raised in my rather plain example above. And it could reasonably be said that the above example is a far more rudimentary psychoacoustic question than the many-faceted question asked in the video: Which of the two tested ANC headphones had more effective noise canceling as perceived by humans?
And, again, that's
not bashing FFT analysis. I genuinely do not understand how the video was interpreted that way, but it seems to be largely due to your conclusion that anyone's "bashing" FFT (which is not the case), and your insistence, then, on defending it to the death from an attack that hasn't occurred.
The conversation with Jacob in the video could open up a whole lot of interesting follow-up discussion about ANC, psychoacoustics, audio measurements, etc. I think we need to move past this idea that FFT has to be defended here, as it does not.
















































")
 .
.
 !
!


