Amazing talk! Thanks so much for uploading it.
Things I don't quite get - how does the surround system that reproduces real world environmental noises record the original sound? It sounds like the ideal test bench would be full sound field synthesis - which is incredibly hard to re-produce and record. It's not binaural but it's replicating the original sound field and then reproducing it. I'm skeptical that a simple array of floor loud speakers, in a single plane, in an anachoeic or quasi-anechocic room would be able to reproduce the full X,Y,Z co-ordinates of sound. I also didn't see a subwoofer there - how are the low frequencies re-produced?
I see any surround system, say a theater 7.1.4 system to be able to re-produce those sounds. I myself (for my own testing) do a similar thing playing background noise on a 7.1.4 theater setup that has an f3 of 6hz. It sounds convincing - but not when you A vs B to a binural recording you make yourself. That contains all the localisation information - but of course that's easy for us with our brain picking up 2 mic inputs from our ears.
Of course it was just a brief video not one on the background noise reproduction system - so more details would be very interesting!
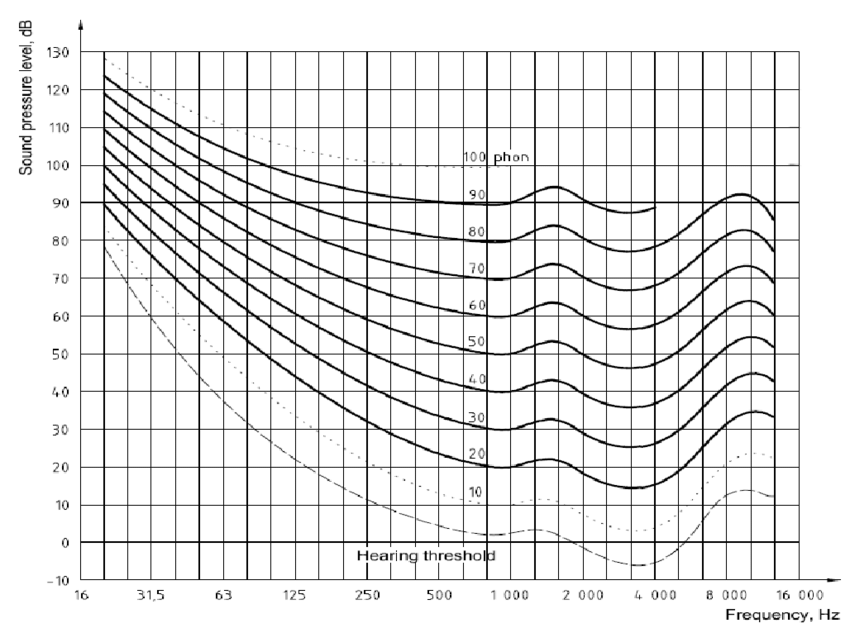
What I like about this approach is that there's an objective criteria to weighting a white noise attenuation curve. Some frequencies are more important than others for the perception of noise. Over ears like the WHXM3 and Bose 700 cancel far more 20-30hz noise than something like the Air Pods Pro or WI-1000x, but on my ears the latter - perceptually - cancel more noise. Things like sex and age matter here too - women are more sensitive to certain frequencies than men. It's a complex psycho-acoustic model if you factor in these additional variables.
Fit is important here too - one thing that's rarely taken into account. Sex is important too - women have longer hair typically so seals are worse. When I grew my hair long it ruined the seal for my over ears. A simple way I test for this is binural mics on my own ears with white noise playing on my 7.1.4 setup - I can then objectively test the attenuation on my own head of my over ears.
But we are 4 generations into ANC headphones and it's not actually improving much anymore. A few db here and there is easily forgotten about. I think we're at the state of the art now and waiting for new silicon to increase the higher frequency attenuation. Apple here could change the game - they have the speed in their chips to push it to higher ranges. The APPs actually ANC out higher frequencies with foam ear tips than silicon. See here for proof: (turn on english subs) so the upcoming overears might really change things. The YTer tested passive attenuation with silicon and foam to discount that as the source of improvement. With foam tips Air Pods Pro are by far my best ANC headphone
Hey
@johnn29 - thanks! And great discussion topic!
We didn't dive too much in to the details of the background noise reproduction system in the video, but I'm happy to share more here.
@castleofargh is spot on. For you guys (and others who are interested), the system complies with ETSI TS 103 224:
https://www.etsi.org/deliver/etsi_ts/103200_103299/103224/01.01.01_60/ts_103224v010101p.pdf (ETSI standards are free to download - so go nuts!

)
That standard does get into the match of matrix inversion etc., so I won't do that here. But the short story is:
- we use the 8mic array on the manikin to record noise events and environments
- we then go back to the lab and use the same 8mic array and manikin to equalize the playback
- the equalization process identifies the impulse response from each loudspeaker to each mic (8x8 matrix of IR)
- apply fancy math to figure out which delays, FIR, IIR filteres need to be applied to each speaker channel to obtain the same frequency and phase output at each of the mics in the lab (which means room effects, speaker/amp/cabling issues are accounted for)
- one you hit "play" on any of your 8ch noise sources, they are then "reassembled" at the mic locations.
A little bit of background:
the original 8mic/8speaker MPNS (Mulit-Point Noise Simulation) system was designed for mobile phone testing and used a mic array that was slightly right side biased - for better or for worse, that how mobile phones get tested: on the right side of the manikin head.
That works well for mobile phones, because their mics are all located along the mobile phone plane.
The standard requires that the spectrum is equalized form 50Hz-20kHz. Decent two-way bookshelf monitors (Klipsch R-51m) can get there, where the EQ portion then compensates a bit. Magnitude and phase of the complex coherence has to exceed 0.9 and +-10deg in a narrower frequency range, but enough to "trick" a mobile phone)
The goal of the standard was to create a method and system that doesn't require a million dollor anechoic room and a 128 loudspeaker ambisonic system. And the succeeded. As pointed out, there is some vertical separation of both the mics and the loudspeakers, so that helps the system more easily recreate some of the vertical noises, but, as also mentioned in the video, this wasn't designed for our subjective enjoyment, nor is it fully 3D capable. It's fun! But there are limitations!

Since the original ETSI TS 103 224 was written, there's been an update that allows for more flexible MPNS systems. One that we use for headphone testing does use a different 8mic array, which focuses the eq spot closely around the ears (close to where the ANC mics are located in the headphone cups).
Now we also typically use a 8.1 speaker system for better lower frequency playback capabilities. And for the more flexible MPNS system, I have seen fantastic coherence numbers out to 20kHz. It's really impressive.
(for reference, the MPNS system also allows you to simply do binaural recordings and playback. Which we can also do using our 8+1 speaker setup. That would give you an even better sensation if you are right in the sweet spot.

)
Thanks again for the interesting question. I hope my response was on point. But I'm well aware I might have triggered a series of follow up questions...

!