Hi Skamp,
I think the reason that your files sound relatively similar and do not really represent the analog output of the tested devices is because ->
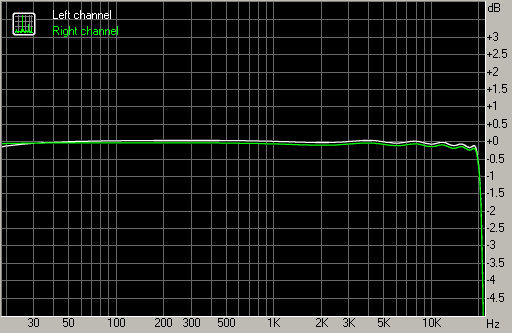
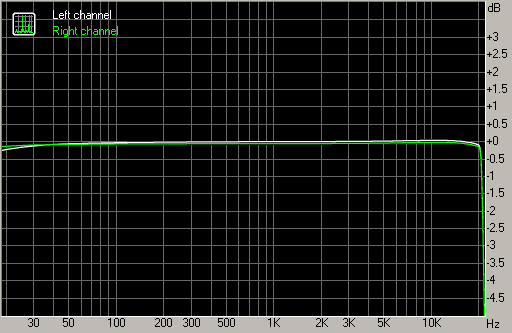
Please take a look at this FFT from a DAC that I made in the late 1990's. This was measured on an Audio Precision System Two by Helmut van Aaken, technician at Thum + Mahr, a german company that sells broadcast equipment.
Here you see the harmonic structure of the overtones that are generated during reproduction. Note that those overtones are well below the quantization of a 16 bit recording.
They are very silent and audio engineers often like to make those harmonics as small as possible. However, the harmonic structure is where the business takes place, not only in their magnitude but moreso in their distribution as such.

On the AP shot you see the 2nd harmonic down at about -105 dB, the third at -120dB, the 4th up a little, the 5th down a bit and so on. Every odd order harmonic in my design is lower than the even order harmonic. This is what makes a sound. Or in other words, this an indication of what makes a sound good.
The human ear is extremely sensitive to the harmonic content of a sound, and by extremely I mean extremely !
Odd harmonics are perceived much louder compared to even harmonics. Odd harmonics cause alert. It is the trick of nature to percieve the cry of a baby or a small child as extremely loud and alerting although the output as such is relatively low.
Whenever an instrument, a voice or a DAC (as in your case) is recorded, the harmonic content falls below the quantisation, that means it is NOT on the recording. Therefore your recordings do not show much the audio quality of the DACs. At least they don't show everything there is.
It is the (undiscovered by most) duty of the reproduction equipment to re-create the harmonic structure, in order to achieve a good sound quality.
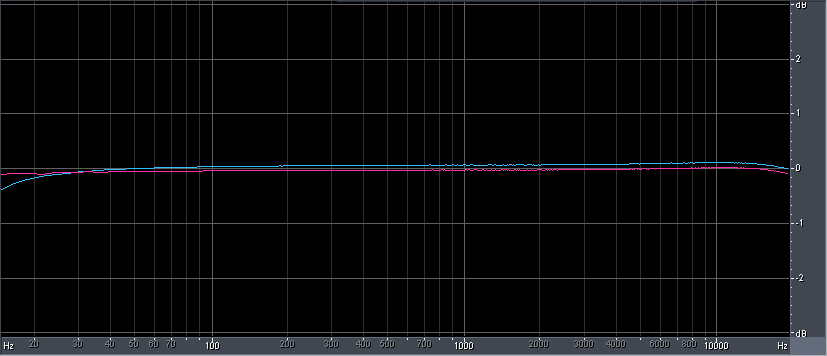
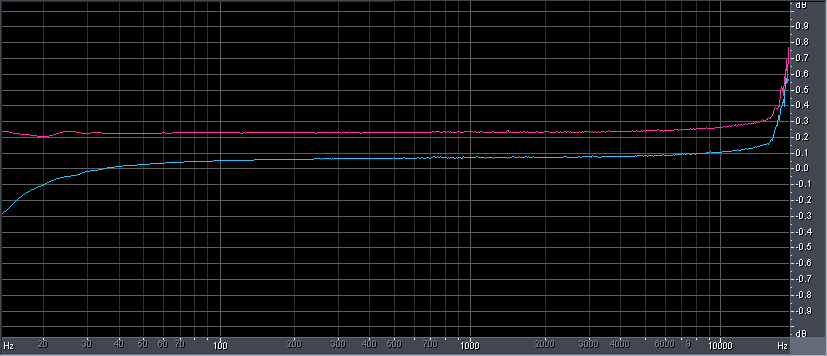
The measurement above is a hint only, because it is primitive. It only measures the harmonic content of one steady frequency and only up to 22kHz. It does not take into account the dynamic behaviour of the harmonics with changing amplitude and frequency. And it also does not show what's happening in the MHz region as every noise is energy, and energy does not get lost into nothing.
This would be subject to a whole new universe of research.
Are you up to it ?
Charles
")












![size]](http://files.head-fi.org/images/smilies/eek.gif[size=13px][/size])


















